Survey Questions and Results
2010/3/17: The survey is re-opened for anyone who would like to
take it. Go here to take it.
Please feel free to send the link to the survey to anyone you
think would find it interesting.
These results will be published in my dissertation. Please contact me if you would like citation information. Please note the small sample sizes.
--Art Munson, 8 March 2010
Respondants were solicited through two email lists: Machine Learning News on
Google Groups, and KDnuggets.
Twenty-four respondants completed the survey. Two respondants used
dummy values for all questions (e.g., zero percent time spent during
all modeling stages); one of these commented that he/she simply wanted
to view all survey questions. (Survey questions were split across
multiple web pages.) I discarded these two responses, leaving 22
survey responses.
Answers for questions are italicized.
- How many *completed* systems have you worked on where data
mining or machine learning were important to success?
A completed system is either deployed or results in significant
contributions to a domain outside of computer science (e.g., a
publication in non-CS journal).
Number of systems (frequency): 1 (6), 2 (4), 3 (5), 4 (2), 5
(1), 7 (1), 8 (1), 10 (1), 40 (1).
- (Optional) Please list key words or phrases that describe your
interests, expertise, and/or background. One phrase or key word per
line.
Suprisingly, almost all respondants completed this question.
The answers were highly varied and included domains like medicine,
robot control, natural language processing, customer modeling and
retention, advertising, and finance.
-
Choose one system you have worked on with a modeling component (most
recent, biggest, most successful, etc.). Estimate the percentage of
time spent in each modeling step (see bottom of
page). Please include both your effort and your collaborators'
efforts, but omit computer time. Rough estimates are
sufficient.

Boxes show the 25th and 75th quantiles of time spent per stage; the
line within each box marks the median time spent. Whiskers show the
minimum and maximum time spent.
The relative time spent in each stage varied greatly by project.
Data collection and preparation were the most time consuming stages,
based on median values (20% and 30%, respectively). Median times
spent on other stages were all around 10%. Interestingly, only 10%
of the effort in a typical project is actually spent learning the
model
-
How important was each step to the success of the system in the
previous question? [Respondant chose one of following for each step:
not important, slightly important, moderately important, important,
or critically important.]

The majority of surveyed practitioners rated all steps as
important or critically important to their systems' successes.
Chart shows the breakdown of importance ratings for each modeling
step. For example, of the 22 total respondants, 12 rated data
collection 'critically important', 4 rated it 'important', 5 rated
it 'moderately important', and 1 rated it 'not
important'.
-
In your opinion, how much energy does the *research community* spend
addressing each modeling step? [Respondant chose one of following
for each step: negligible energy, a little energy, moderate energy,
lots of energy, or enormous energy.]
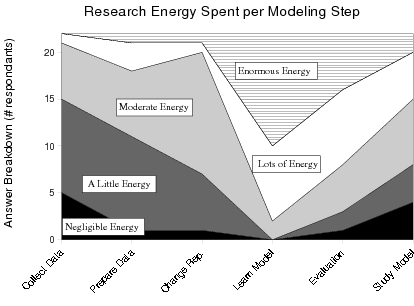
Most surveyed practitioners felt that the machine learning and
data mining research communities spend the most energy on how to
learn a model from data. Most respondants rated the communities as
spending 'moderate energy' or less on the modeling steps
preceding and following learning a model. In contrast 19 of 22
respondants felt the community spent 'lots of energy' or
'enormous energy' on how to learn a model.
- (Optional) Additional Comments / Feedback:
Only 10 respondants left comments. Two said they found the
survey interesting. Six respondants left comments elaborating why
they felt certain modeling step(s) were the most important for
success in the domains they worked in.
- Data Collection
- (Stage 1 in top figure.) Not raw data
collection, but any work team did to gather data into hands of
analysts.
- Data Preparation
- (Stage 3 in top figure.) E.g., data
integration and fusion, data cleaning, handling missing
values.
- Change Data Representation
- (Stage 4 in top figure.)
E.g., rescaling and normalizing features, transforming prediction
target, feature selection, dimensionality reduction.
- Learning a Model from Data
- (Stage 5 in top figure.)
E.g., posing the problem, algorithm selection or design,
hyper-parameter selection
- Performance Evaluation
- (Stage 8 in top figure.)
Accuracy and confidence in predictions.
- Study Model
- (Stage 9 in top figure.) E.g., to
understand the model, to discover knowledge about domain theory,
or to identify regions where model makes risky extrapolations.