CS 612 -- Homework 1
Due: February 22, 2005
Introduction
In this assignment, you will be asked to discover the cache parameters
of your machine, analyze the performance effects of various types of
codes on your machine, obtain an optimized MMM code for your machine
and finally use this experience to create your own optimized MMM
kernel. Note that this assignment is easiest to complete if it is all
done on a P6-class machine (i.e. Pentium 2 or Pentium 3). The files
for completing this assignment are linked to within the assignment.
Problem 1 -- Cache Parameters
In this portion, you will use a tool developed by Kamen Yotov, called
X-Ray, to determine the cache parameters of the machine you are
using. First, read this paper to learn
how to download and use X-Ray. Then run X-Ray to determine the cache
parameters of your system. Find all parameters you think relevant to
optimization for cache performance. If possible, verify the results
returned by X-Ray by comparing to hardware manuals, or information on
the web. Turn this information in as part 1. You will also need it to
complete later parts of the assignment.
For further discussion of X-Ray (the papers referenced in the above
document, etc), check here.
Problem 2 -- Miss Ratio as a Measure of Cache Effectiveness
The miss ratio of a program provides a measure of how
effectively the program utilizes your cache, and, in some sense, how
efficient the program is. Intuitively, the fewer times a memory access
has to go all the way to main memory, faster the program will run. The
miss ratio measures exactly this. In this problem, we will examine the
miss ratio for a common linear algebra problem, Matrix Matrix Multiply
(MMM), and see if the results give us some ideas as to how to best
exploit knowledge of cache parameters.
In order to compute the miss ratio, we will use performance
counters. Most architectures provide access to counters which measure
such things as memory accesses and cache misses. We will use this
information to determine the miss ratio for various versions of MMM.
If the machine you are testing on is in the P6 family, you
can use this library to access the
hardware counters. If you are using a Pentium 4 class machine, you
will need to determine how to access the performance counters
yourself. If you would like to use a PowerPC based machine, email
Milind for information regarding the performance counters.
Once you are familiar with the access and use of the performance
counters for your machine, write a simple, triply-nested loop MMM
program, and run all 6 loop-orders for varying array sizes to produce
a graph that looks like:
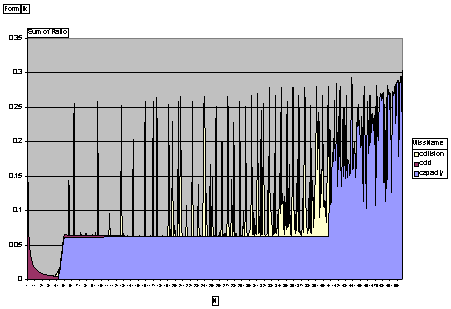
Explain the changes in the miss ratio for the graph. Discuss why some
loop orders perform better than others, and explain any sudden changes
in miss ratio. Finally, comment on how this information might provide
optimization opportunities.
Problem 3 -- Empirically Optimized Cache-efficient Libraries
Rather than hand tuning linear algebra libraries to each architecture
individually, a common approach is to use empirical optimization to
automatically generate a high performance implementation of the
library. The standard linear algebra library is BLAS (Basic Linear Algebra
Subprograms), and the most common empirical optimization tool for BLAS
is ATLAS (Automatically
Tuned Linear Algebra Software). In this problem, you will use ATLAS to
generate the BLAS libraries optimized for your system.
First, download and install ATLAS, following the documentation on
their website. Note
that if you are using a Windows machine, you will need to also
download and install Cygwin. After installing (and running) ATLAS, you
will have generated a static library which contains the BLAS
subroutines.
Now write a simple wrapper class to perform MMM
using square matrices, and calling the BLAS routine for matrix matrix
multiply. Reference this
document to figure out how to call the generated routines (note:
you are looking for the BLAS operation that allows you to do C =
alpha*A*B + alpha*C without any constraints on A, B or C). For further
help, here
is a description of what the various arguments mean, and here
is a sample program that shows how to call a similar BLAS function.
Once you get your code working, run it for various matrix
sizes, and plot your results.
Problem 4 -- Write Your Own
Now you will try your hand at writing an efficient MMM kernel. Read
this paper
by Yotov et al. Focus on the technique of writing parameterized
MMM. Once you are comfortable with tiling and unrolling to efficiently
use registers and cache, write your own implementation of MMM. Find
the parameters in any way you would like - e.g. using a model or
experimentation - that give you the best results. Run your kernel for
various matrix sizes, and plot your results. Compare them to the
results of Problem 3.
If you were able to complete Problem 2
on the same machine that you completed the rest of the assignment, for
extra credit, comment on how the parameters you found relate to the
cache performance you noted in Problem 2.
Submission
For Problem 1, submit the cache information you discovered. For
Problems 2 and 3, submit your discussions along with the plots. For
Problem 4, submit your discussion, plots of data and your source code.