Numerical Diagnostics¶
In addition to visualization, we can use numerical properties of residuals to assess the quality of regression. We will not prove these properties mathematically. Rather, we will observe them by computation and see what they tell us about the regression.
All of the facts listed below hold for all shapes of scatter plots, whether or not they are linear.
Residual Plots Show No Trend¶
For every linear regression, whether good or bad, the residual plot shows no trend. Overall, it is flat. In other words, the residuals and the predictor variable are uncorrelated.
You can see this in all the residual plots above. We can also calculate the correlation between the predictor variable and the residuals in each case.
correlation(heights, 'MidParent', 'Residual')
That doesn't look like zero, but it is a tiny number that is 0 apart from rounding error due to computation. Here it is again, correct to 10 decimal places. The minus sign is because of the rounding that above.
round(correlation(heights, 'MidParent', 'Residual'), 10)
dugong = dugong.with_columns(
'Fitted Value', fit(dugong, 'Length', 'Age'),
'Residual', residual(dugong, 'Length', 'Age')
)
round(correlation(dugong, 'Length', 'Residual'), 10)
Average of Residuals¶
No matter what the shape of the scatter diagram, the average of the residulas is 0.
This is analogous to the fact that if you take any list of numbers and calculate the list of deviations from average, the average of the deviations is 0.
In all the residual plots above, you have seen the horizontal line at 0 going through the center of the plot. That is a visualization of this fact.
As a numerical example, here is the average of the residuals in the regression of children's heights based on parents' heights in Galton's dataset.
round(np.mean(heights.column('Residual')), 10)
The same is true of the average of the residuals in the regression of the age of dugongs on their length. The mean of the residuals is 0, apart from rounding error.
round(np.mean(dugong.column('Residual')), 10)
SD of the Residuals¶
No matter what the shape of the scatter plot, the SD of the residuals is a fraction of the SD of the response variable. The fraction is √1−r2.
SD of residuals = √1−r2⋅SD of y
We will soon see how this measures the accuracy of the regression estimate. But first, let's confirm it by example.
In the case of children's heights and midparent heights, the SD of the residuals is about 3.39 inches.
np.std(heights.column('Residual'))
That's the same as √1−r2 times the SD of response variable:
r = correlation(heights, 'MidParent', 'Child')
np.sqrt(1 - r**2) * np.std(heights.column('Child'))
The same is true for the regression of mileage on acceleration of hybrid cars. The correlation r is negative (about -0.5), but r2 is positive and therefore √1−r2 is a fraction.
r = correlation(hybrid, 'acceleration', 'mpg')
r
hybrid = hybrid.with_columns(
'fitted mpg', fit(hybrid, 'acceleration', 'mpg'),
'residual', residual(hybrid, 'acceleration', 'mpg')
)
np.std(hybrid.column('residual')), np.sqrt(1 - r**2)*np.std(hybrid.column('mpg'))
Now let us see how the SD of the residuals is a measure of how good the regression is. Remember that the average of the residuals is 0. Therefore the smaller the SD of the residuals is, the closer the residuals are to 0. In other words, if the SD of the residuals is small, the overall size of the errors in regression is small.
The extreme cases are when r=1 or r=−1. In both cases, √1−r2=0. Therefore the residuals have an average of 0 and an SD of 0 as well, and therefore the residuals are all equal to 0. The regression line does a perfect job of estimation. As we saw earlier in this chapter, if r=±1, the scatter plot is a perfect straight line and is the same as the regression line, so indeed there is no error in the regression estimate.
But usually r is not at the extremes. If r is neither ±1 nor 0, then √1−r2 is a proper fraction, and the rough overall size of the error of the regression estimate is somewhere between 0 and the SD of y.
The worst case is when r=0. Then √1−r2=1, and the SD of the residuals is equal to the SD of y. This is consistent with the observation that if r=0 then the regression line is a flat line at the average of y. In this situation, the root mean square error of regression is the root mean squared deviation from the average of y, which is the SD of y. In practical terms, if r=0 then there is no linear association between the two variables, so there is no benefit in using linear regression.
Another Way to Interpret r¶
We can rewrite the result above to say that no matter what the shape of the scatter plot,
SD of residualsSD of y = √1−r2
A complentary result is that no matter what the shape of the scatter plot, the SD of the fitted values is a fraction of the SD of the observed values of y. The fraction is |r|.
SD of fitted valuesSD of y = |r|
To see where the fraction comes in, notice that the fitted values are all on the regression line whereas the observed values of y are the heights of all the points in the scatter plot and are more variable.
scatter_fit(heights, 'MidParent', 'Child')
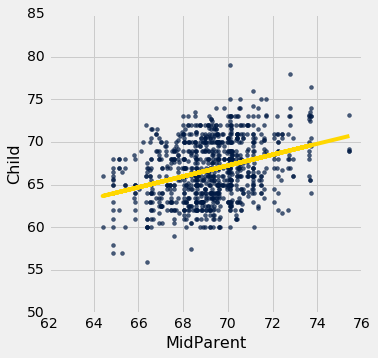
The fitted values range from about 64 to about 71, whereas the heights of all the children are quite a bit more variable, ranging from about 55 to 80.
To verify the result numerically, we just have to calculate both sides of the identity.
correlation(heights, 'MidParent', 'Child')
Here is ratio of the SD of the fitted values and the SD of the observed values of birth weight:
np.std(heights.column('Fitted Value'))/np.std(heights.column('Child'))
The ratio is equal to r, confirming our result.
Where does the absolute value come in? First note that as SDs can't be negative, nor can a ratio of SDs. So what happens when r is negative? The example of fuel efficiency and acceleration will show us.
correlation(hybrid, 'acceleration', 'mpg')
np.std(hybrid.column('fitted mpg'))/np.std(hybrid.column('mpg'))
The ratio of the two SDs is |r|.
A more standard way to express this result is to recall that
variance = mean squared deviation from average = SD2
and therefore, by squaring both sides of our result,
variance of fitted valuesvariance of y = r2