CS 6670 Project 1
by
Ivaylo Boyadzhiev (iib2)
1. Custom features detector/descriptor (details):
My feature detector and custom descriptor use ideas from both MOPS and SURF.
- Features detector:
- Use Harris corner detector to assign "corner strength" values to each pixel in the original image.
- Use treashold (1e-5) and local maximum check (in 5x5 window) to reduce the number of interest features.
- I implemented the adaptive non-maximum suppression (ANMS) to
further reduce the number of
interest feature points and achieve more uniform distribution of features around the image. - Use the dominant eigenvector from the Hessian matrix to
determine the canonical orientation for each
feature point. - I enhanced this idea, by discretizing the angle corresponding
to the dominant vector (I used bins
with size of 10 degree), that way we will tolerate small variations in the angle (seems to slightly
boost the performance, +4% for the average AUC on all test cases).
- I tried using the HoG (Histogram of Gradients), but it did
not work that well, maybe it works well
in combination with other techniques, that I haven't implemented (e.g. clone the same feature with
different orientation angles).
- Features descriptor:
- My features descriptor is similar to SURF (but for a constant scale, as I haven't implemented scale invariance).
- The first step is to get the canonical orientation of a 40-by-40 window around the feature point.
- Select a slightly bigger (but at least 40 * sqrt(2)) window
around the feature and rotate it using backward
rotation with bilinear interpolation (aka. for each point in the destination image, use the inverse rotation
to determine the set of points from the source image that might contribute to its value). - Subsample 20-by-20 window around the canonical orientation of the feature point.
- Divide this windows into 4-by-4 cells (each of size 5-by-5) and compute dx, dy, |dx| and |dy| for each of them.
- dx is the sum of the x gradients, |dx| is the sum of the absolute values of the x gradients (same for dy).
- I used Sobel_X and Sobel_Y convolution filters to calculate and smooth the gradients.
- My custom descriptor will be formed by concatenating the
vectors (dx, |dx|, dy, |dy|) for each of the 4-by-4
cells, so the descriptor size will be 64 (4x4x4). - As we are working with derivatives, my custom descriptor will
be invariant to changes in brightness (I' = I + c),
but in order to make it invariant to changes in contrast, we need to transform it into a unit length vector (that way,
we can handle changes in illumination like I' = I*a)
2. Major design choices:
First of all, my initial idea was to implement something similar to what SIFT is doing. I actually wrote the code, but it did
not work that great for me (either I had some bug, or you need all the components of SIFT in order for the magic to happen).
I also tried using HoG for determining the orientation of patches, but (in my tests) it was worse than using the dominant
eigenvector.
I decided to discretize the possible orientation angles (using 36 bins, each of size 10 degrees) in order to achieve some level
of robustness (worked out pretty well in practice).
My second choice for descriptor was SURF, as its idea seemed very elegant and efficient to implement.
I decided to implement Adaptive Non-Maximum Suppression in order to reduce the number of features and this actually
improved the results, as after applying this filter, we would work with smaller, uniformly distributed set of features that
have relatively high values for the corner strength function.
3. Performance:
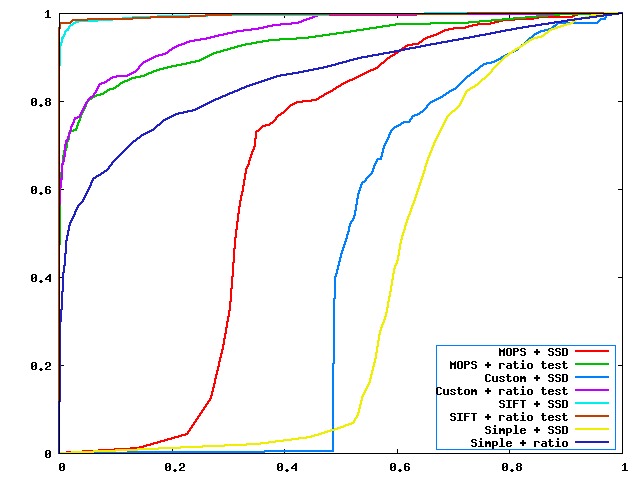
- Yosemite data set
- Harris corner strength function
- ROC curve
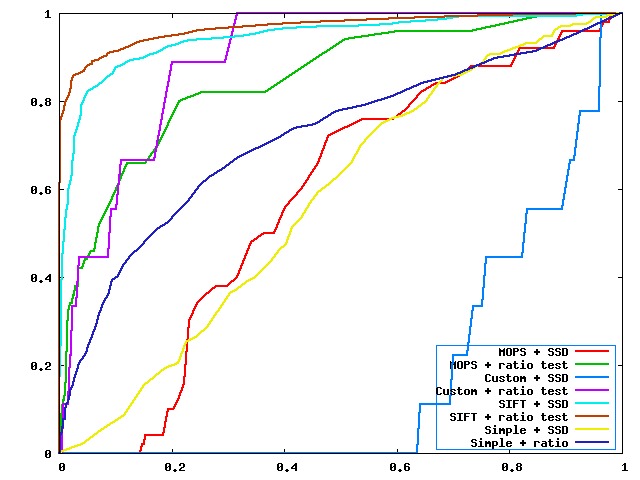
- Graf data set
- Harris corner strength function

- ROC curve
- Average AUC values for the 4
data sets [bikes, graf, leuven, wall]
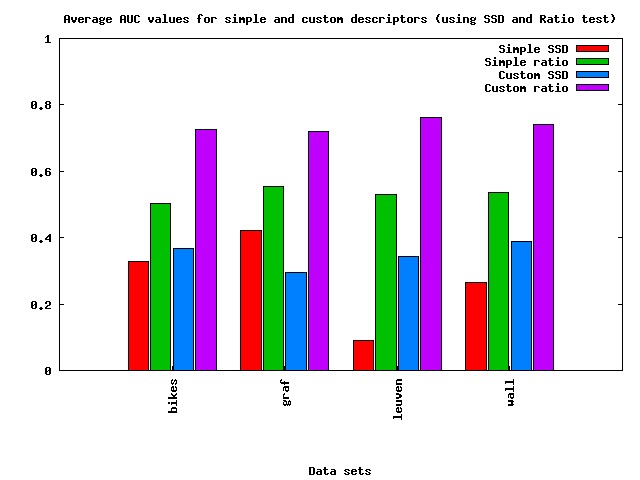
Data Set
Simple [SSD]
Simple [ratio]
Custom [SSD]
Custom [ratio]
bikes
0.329120
0.503578
0.367937 0.726015
graf
0.422233
0.555390
0.296382
0.720177
leuven
0.090206
0.531102
0.343536
0.762290
wall
0.265079
0.535482
0.387502
0.740948
4. Strength and weakness:
- My descriptor is not scale invariant and I'm certainly missing some important features.
- My descriptor seems to be very sensitive to the choice of
matching function, the difference
between the SSD and ratio strategies is huge (maybe kNN will be even better for my descriptor,
but I did not have time to test with that). - My custom detector/descriptor is pretty fast:
- I'm using ANMS to reduce the number of interest features.
- My descriptor works only on 1 scale and basically computes
derivatives, which can be
done very efficiently (one convolution with an appropriate filter). - For the provided data set, my custom descriptor is at about 10%
worse than the state of
the art SIFT.
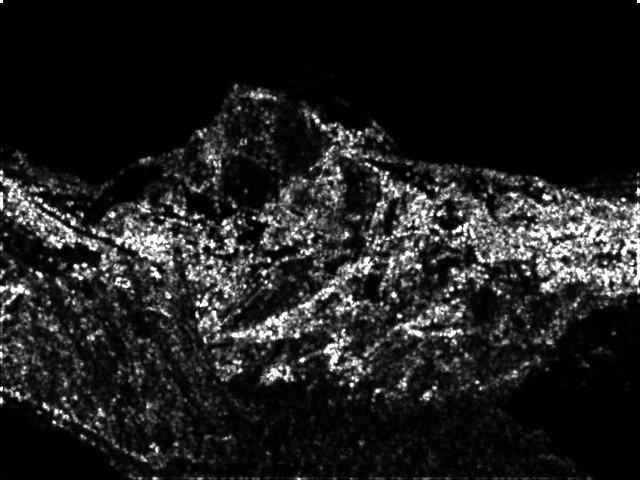
5. My test case:

- I added the function save_sift(), that converts our match
structure to the one, that SIFT works with.
- The picture shows 60 matches, found and described with my
feature detector and my custom descriptor.
Matches are paired up using the small matching program, that comes along with SIFT. - I did not have time to create homography matrix for this two set
of images, so we can only judge this
test by looking into it and visually it seems plausible.
6. Extra credit features:
- I implemented Adaptive Non-Maximum Suppression (ANMS)
- SURF
paper
- MOPS paper
- SIFT paper
- Lecture notes.