Date:
12/18/1998
Name of group: Group 4, Phonetics
Team members: Eliot Gillum, Jason Pettiss
Task: Team 10, IP Telephony QoS Monitoring
IP Telephony Quality of Service Monitoring
Final report
Table Of Contents:
IP
Telephony Quality of Service Monitoring
I.
Goals
II.
Accomplishments
III.
Problems & Issues
IV.
What We Learned
V.
Learning From Mistakes
VI.
Interface Specifications
VII.
Advice to the Course Staff
VIII.
References
I. Goals
The goal of IP Telephony Quality of Service
(IPTQoS) components is to provide IP telephony users with an idea of the
quality of service they can expect from the network. Additionally, it provides
a real-time view of the network’s quality of service parameters, useful
for diagnostics and capacity planning.
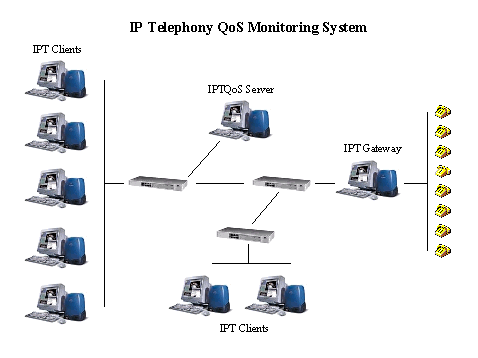
IP telephony applications run an IPTQoS client
in the background, which connects to a central server that directs the
intelligent probing and monitoring of the network segments between participating
IPT hosts (see figure). With the clients actively exploring routes between
other IPT hosts, the server can, by merging the information it receives
from the clients, provide useful data pertaining to IP Telephony. It can
answer questions such as "Can I call someone right now and have a good
quality call?" or "Can I and three other people conduct a conference call?"
or even "What does the network look like?"
There are many factors that contribute to
overall quality of service. Just because the network is currently traffic-free
between two nodes does not mean it will be in the near future. Response
times, throughput, and packet loss ratios can vary over time—but even current
estimates of these are generally unavailable to most applications. This
is where IPTQoS comes in. Our components expose interfaces for interested
applications to obtain a simple red-light/green-light for communications
between multiple parties or to obtain more detailed latency/bandwidth data
gathered over time. Both of these provide a better indication of quality
of service than otherwise available (trial and error).
An interesting feature that we provide to
administrators (partially because we couldn’t resist doing so) is using
graph theory to gain an understanding of the underlying network topology
between clients and the gateway. We can display this topology in a graph
with latency and bandwidth of links indicated by features of the link (color
and line width). This can very clearly show what bottlenecks exist.
In order to not adversely affect network performance,
the server would cut back the activity of the quality of service routines
if it determines the quality of a call is in danger. During idle periods
however, the server can conduct bandwidth tests and other active, resource
greedy tests. Note that traffic on the network due to IPTQoS wouldn’t increase
with the square of the clients using its services because of server optimizations.
Clients on the same subnet share the same data from the gateway and only
run when necessary. Routes where the QoS hasn’t changed much don’t have
to be monitored as often. QoS information is only obtained between clients
and "interesting parties". In a very advanced scenario, it would make sense
that two different gateways with IPTQoS could share information in common.
II. Accomplishments
Our project was largely successful.
We were able to have a fully functional server communicating with multiple
clients who gathered real-time information on the network and reported
it to the server. It successfully gathered QoS information between all
the clients and the specified gateway machine. In reality we specified
the gateway as a number of different machines at different distances from
the local area networks we had access to. We saw that the clients gather
route and ping time information and communicate it to the server. Then,
using the topology display tool we wrote, NetworkTopologyStub,
which wraps a ShowTopology
object, we were able to graphically display the topology the clients had
discovered.
The server works by accepting connections
and processing them based on what the message type specified for the connection
was. There are six types of messages:
| Type |
Initiator |
Response? |
Explanation |
| Hello |
Client |
No |
Sent when
a QoS client logs on to the server |
| Goodbye |
Client |
No |
Sent to
the server when the client is shutting down |
| Query |
Client |
Yes |
Represents
a query from an IPT application about the quality of the network |
| Report |
Client |
No |
Sent when
the client has new information to give about route |
| Monitor |
Server |
No |
Sent when
server has a new list of people the client should be monitoring |
| GetGraph |
ShowTopology
object |
Yes |
A request
for the graph representing the current network status. The response is
a serialized iptqGraph |
There were only two things that we didn’t
accomplish. First, we didn’t get a chance to implement any of the server
optimizations that would have allowed the server to scale to large amounts
of clients. As it stands, the server is implemented using Java Hashtable’s
so, in terms of data structures, the server does scale. What is lacking
is the code to optimize who the clients should monitor. Second, the bandwidth
testing classes were not stable enough at the time of the demo to include
them. Because we are underlying components loaded into other clients’ process
spaces, we felt stability was a major issue. We tested our components under
multiple configurations and even in a 4-hour stress test, and everything
worked great. However, we had to resort to a secondary and less accurate
method of indicating bandwidth.
III. Problems & Issues
We had a number of issues during
the course of the semester, which is only expected. Problems were both
technical and interpersonal in nature. We started out as an all Java application,
intending to use some sort of RMI communication. The group decided it would
be better for each team to provide their own proxy-stub communication code.
When we returned from Thanksgiving, with substantial
work on the client, we realized that ICMP wasn’t going to work out in Java.
Making calls on the DLL proved hard enough, but the structures the DLL
was expected us to pass as parameters were all but impossible to create
in Java. Finally, realizing that multiparty (our primary client) was planning
to code in C, we decided the client would have to be redone in C.
Getting Java code to talk to C code and vice
versa is not exactly Happyland. The languages are similar but very different
in crucial areas (namely C operates primarily with pointers whereas in
Java everything is a reference), and this lead to difference in opinions
on how the communication protocol should work. Naturally there are things
easily done in either language that are tedious in the other. We decided
to communicate with integer-sized blocks. IP address would fit within this,
as would most other data we used.
We had the usual fair of language-specific
issues, such as J++ 6.0 crapping out on us, and Socket.getOutputStream
returning an "invalid file descriptor". When we switched to a lower version
of Java, this was solved, but then we realized we wouldn’t be able to use
the newer AWT event model. It took awhile to realize that arrays are handled
quite differently in Java than in C.
Other issues included learning the differences
between Winsock and UNIX socket programming, byte-ordering issues, and
various ICMP issues. Performing ICMP ping and traceroute was by far the
most technically challenging code, although algorithmically the network
topology code was much more complex. Tweaking the exact method to accurately
determine network latencies also took awhile—quite frequently we found
that the first few pings take substantially longer than later pings, as
if we were ‘opening up a pipe’. However, the more pings we send, the more
bandwidth we use up, and the longer it takes to gain data on a particular
node. The final solution was to use traceroute first with three probes,
and then follow up with a round of 5 small pings to each of the hops along
the route (in order). By the time we’d reached the destination, we’d already
sent the 30 or so packets the network needed to ‘settle down’.
Naturally we also had a fair share of dealing
with other teams. Many teams couldn’t see our value initially, and in fact
most didn’t realize our real potential (and plan to integrate us), until
too late. Others that were planning to use us ran out of time to include
us, despite our simple plug-in interface and sparse API.
None of these problems were a major deterrent
or discouragement, and none were unexpected in the sense that we knew things
would come up. We felt we learned something valuable from every problem
or issue that arose.
IV. What We Learned
The scope of this project was large and we
learned a great deal of things from it. We gained not only technical knowledge,
but how to deal with large projects where you have to collaborate with
many other busy people who are also dealing with other coursework. We ran
into numerous technical issues during this project, all of which we learned
from.
One of us is most comfortable in C, and he
wrote the server in Java. The other is more comfortable in Java, and he
got to write the client in C. This was definitely a learning experience
for both of us. We learned that Java uses network-endian byte ordering
and that Java arrays are different from what you’d expect in C. We learned
that Winsock network code is very similar to UNIX network code but by no
means identical. One finds differences in many trivial and annoying ways,
and a few major ones, namely the richer threading model in Windows.
We learned that remote procedure calls (RPC)
are a very powerful abstraction and a nontrivial issue to implement. One
of us who is familiar with COM always took RPC for granted, until we ended
up having to do something like this on our own. Even in our limited and
very specific case establishing a protocol to do so was a major detail.
Given the nature of our project we had to
learn a significant amount about ICMP and the types of packets that are
sent via ICMP. We learned that this is something to attempt with Java and
even in C is very complex. Not only did we learn about ping and traceroute,
but now we have a program far superior to the Microsoft-provided utilities.
Quality of service is naturally a broad topic,
and there was much to research and learn about this topic. From what type
of data to gather to how to correlate the multiple vectors of data to what
applies to our IP Telephony clients, there was a great deal to do and learn.
Collaboration was of course another area that
we had to focus on. We learned that software is only useful if it is used,
and if it is simple enough to use. At the end we weren’t fully integrated
into other people’s products despite our simple plug-in nature; they either
realized our potential too late or were too busy fixing bugs to do so.
We also were limited in complexity by the time others had to learn how
to use our components. Rather than returning a structure of detailed quality
of service info, we return a boolean yes or no on whether we predict a
call will be good.
Getting twenty people to agree on anything
is impossible, especially if you’re picking a meeting time. But it helps
to have great managers who aren’t necessarily technical wizards but who
have a firm understanding of the fundamentals and who have the guts to
set milestones and stick to them, and forcefully encourage people to meet
those deadlines. They realized early on that integration would be the hardest
part, and worked on getting us towards that mark as soon as possible. But
even the best-laid plans have a tendency to run amok. A few things we learned
in summary about working in large groups:
-
Never underestimate the complexity of integration
-
Never underestimate Murphy: he will find plenty
for you to debug
-
Time is the major limiting factor—we could do
so much, but other groups don’t have the time to implement calls into your
new APIs. You have to get strict and ‘feature freeze’ at some point so
that debugging can really begin.
It is very hard to focus on other coursework,
especially that for boring classes, with such an interesting class. We
learned that starting early and making small progress each day is probably
a lot easier on our mental health than starting two days before the project
is due and struggling to come up with a stable working version.
V.
Learning From Mistakes
We made a good deal of mistakes,
which means we must have learned a heck of a lot (which we did!). Many
technical problems, ranging from common to obscure, were caused by simple
errors on our part. Not knowing that Java allocates space in an array but
for classes, but doesn’t actually create any classes, or forgetting that
the ‘==’ operator isn’t overloaded are examples of Java mistakes. C mistakes
include converting integers to host order to send (and then to network
order when they come in), or converting IN_ADDR’s to network order, and
not reversing the byte order on the WSAStartup() version parameter (to
ask for Winsock v1.2 you send it a word of 2, 1).
As far as dealing with people, in the future
we will work harder to set our interfaces in stone earlier, and get people
to use and conform to those interfaces as soon as possible. We would also
like to say that we are going to leave more time in the future for feats
such as debugging and integration, but every program manager’s pipe dream
is that his coworkers will actually live up to resolutions such as that
(hint: they won’t). We did gain some understanding of how important clear
and frequent lines of communication are, and this only increases with the
number of people. A mistake we made was thinking that twenty people meant
twenty times the work of one person, and so time wouldn’t be as much of
an issue as including technical features. But as it turns out, the more
people you have, the more overhead involved, and in the end time
is the overall limiting end-all and be-all of our industry (other than
Turing, of course).
VI.
Interface Specifications
Provided to Team
6 (Management) as a Java stub, 1 API:
void ShowNetworkTopology(String sConfigFileName);
Any Java client can include a stub
and call this function to display the network topology, which will be computed
by the server and sent to the client.
Provided to Clients (Team
8, Multiparty) as a C++ DLL, 4 APIs:
HRESULT InitIptQosMon(char* szConfigPathname);
Called to initialize IPTQoS services.
Accepts the pathname of the IPTQoS configuration file as a parameter. Returns
S_OK (0) for success, or an error code otherwise.
HRESULT ShutdownIptQosMon();
Called to cleanup and shutdown IPTQoS
services before exiting your application. Returns S_OK (0) for success.
An error code may be ignored.
int isCallGood(DWORD clientIPs[], int numClients,
int bitrate);
This is the primary use of our service.
It determines if the network can support a good quality phone call between
the client and the listed IP’s at the given bitrate. If more than one IP
is listed, a multiparty conference is assumed. This function takes into
account latency and loss rates as well as bandwidth concerns. Return can
be treated as Boolean (0 for ‘No’, non-zero for ‘Yes’).
HRESULT getClientQosInfo(DWORD clientIP, char*
szDestStr, unsigned int buffsize);
This can be called to obtain detailed
information about network parameters. It writes a user-readable string
to szDestStr. Returns S_OK (0) for success, (S_OK+1) if the buffer was
not large enough to hold the entire message, or an error code otherwise.
Two additional APIs are provided
for debugging purposes:
void SetIptQosLocalMode(BOOL bLocalMode);
Call for InitIptQosMon. If parameter
is TRUE, no communication with the server will take place. isCallGood will
return random results for testing.
void SetIptQosQuietMode(BOOL bQuietMode);
Call at any point to turn debug
output from the DLL on or off.
VII.
Advice to the Course Staff
All in all, we thought this was
a very interesting project and certainly is a much greater learning experience
than simply implementing an existing protocol. Speaking from an application
team’s point of view, I’d have to say our guidelines were very loose. That
let us run free and explore our avenues, although we didn’t understand
how we were going to be graded. Maybe this was a plus, because we just
focused on doing the best we could, rather than matching to a test bench.
"A complete integrated IP telephony system
involving over 20 students working under their own direction". A recipe
for disaster or a really cool idea for a semester project, depending on
who you are. This is the kind of thing that you can talk to interviewers
about, and in our case it was a really cool idea for a semester project.
A brief comment about the puzzles as they
pertain to the project. They were sometimes a bit vague or poorly defined,
and although each was a great learning experience, they had the effect
of encouraging people to put off real work on the project until after puzzle
5 was out of the way. This really isn’t recommended behavior.
Finally, there was confusion about the machines
we had access to and what sort of access we had to those machines. For
example the group as a whole decided not to use RMI or DCOM on the grounds
that even if we learned how, we wouldn’t be able to develop in the CSUG
lab because of registry permissions. As it was, each group was left to
their own devices to implement proxy-stub code, basically writing the same
thing 10 times. Amazingly, integration went off surprisingly smoothly—I
guess the puzzles trained us well.
VIII.
References
http://java.sun.com/docs/
Prof. Jamin, Univ. Michigan
jamin@eecs.umich.edu
http://irl.eecs.umich.edu/jamin/research/
ftp://ftp.ee.lbl.gov/
Siyan, Karanjit. Inside TCP/IP, Third Edition.
New Riders Publishing. Indianapolis, IN. 1997.
(C) 1998 Jason Pettiss, Eliot
Gillum for Cornell University CS519: Advanced Network Engineering
Last changed: 12/18/98
6:45AM