Group 5: MIA
Anurag Sharma, Charlton Sun
Team 6: Management
Final Report
1. What did you set out to do? (1-2 pages) Use a figure and accompanying text to describe what you set out to do. You can reuse part of your first report if you wish. You should have sufficient detail so that someone who is not familiar with the project would still be able to understand the scope of your work. For instance, imagine giving this to a friend who is not in the class--write something that this person would be able to understand without having to ask you for help.
Our goal in this project was to effectively manage a group of twenty people (including ourselves) during the construction of a full scale Voice over IP, Telephony system. Besides the Management team, the system consisted of nine other components: Data Exchange, Signaling, Gateway (the IP to Telephone Network doorway), Billing Service, Directory Service, and four applications groups.
The first five components had unique requirements, and all of the components were required to interface with each other to form the complete system. The applications were then supposed to use this Voice over IP system to provide a variety of end-user services such as voice-email, multi-media audio conferencing and whiteboard, online slide presentation and lecture service, and a white pages service.
The inner core of the system consisted of DataX, Signaling, and Gateway. These three services provided the base functionality that allowed us to make telephone calls from an IP network to a phone network. Sitting on the periphery of these components, were services such as directory, billing, and management, whose respective functions consisted of address lookups and address maintenance, call billing and billing records maintenance, and passive and active system administration.
Our work within the system consisted of two seemingly disparate, yet related aspects. Our primary function as management was to ensure code consistency during system design. We had to ensure that common interfaces between different components matched in definition. Furthermore, we had to guarantee that teams were notified of relevant information as soon as possible, when a change occurred in the established definition of an interface. We were not asked to play a significant role in system design. Instead, we were supposed to be the “clearing house,” where all definitions were brought for consistency checking.
Our secondary role consisted of designing a Network Management application, which would passively monitor the entire system and, at times, attempt to actively adjust certain components of the system. This application was supposed to serve as a system administrator’s tools, where a snapshot of the entire system may be presented at any given time. To write this system, our team was supposed to poll other teams’ interfaces for relevant information.
In our first report, to address these issues, we came up with the following ideas. For the group management role we chose to do the following tasks:
In addition to the role defined by the project description, we wish to take on additional tasks to assist in areas that are common to all application development. This includes providing speech-to-text and text-to-speech conversion services. Since these services will be used by each application, we consider it best if management spends some effort in developing them, using existing API’s, instead of having each application team repeat the work.
Secondly, we wish to provide a common voice data format. Since the data exchange team considered this beyond their scope, and it was up to each application team to re-implement this functionality. We consider it best if management designs a small Java package which will provide a consistent standard which each application team can build upon.
Management strongly feels that the converters and data format package will allow the application developers to concentrate on the more critical aspects of their products.
For the Network Management Application we came up with the following first cut specification:
Pseudocode:
Our pseudocode primarily describes how our Management System will work with the individual processes that make up the complete architecture. The general design of the pseudocode is a client/server model, where the central Management System is the server. The clients reside with each of the individual processes (the processes being Gateways, Signal components, Directory Services, Applications, etc.). Therefore, each process will have a “management child” thread associated with it, this thread will sleep most of the time, and will only be woken by the process if some event happens which the management software should know about. In this case, the thread will be notified with some event object, which it will direct to the central server through a secure connection.
[Code from the first Report has not been included]
2. What did you actually accomplish? (2-3 pages) Write down exactly what you managed to get done by the time of the demo. Did you achieve all the goals you set out to do? Did you do something that you didn't expect to be doing when you started?
We found ourselves taking a larger part in the system design than we had expected. As the semester passed, we found ourselves having an intimate knowledge of protocols that our Signaling group was using, and the protocols which were used by the Directory and Billing groups to run their own services. We found ourselves working more closely with the core teams, than with the applications teams. To the applications teams, we simply presented the interfaces defined by signaling (which abstracted data exchange and supplied a single, unified interface to the applications). However, with the core groups we found ourselves mediating in issues ranging from address definitions, to advising on protocol specifications to make sure that other components had the necessary information that they needed.
We disregarded our earlier role, which consisted of designing the text-to-speech package, instead we took a more active role in managing and delegating work to the group. Our Signaling and Gateway teams were very strong, and self-starters. Therefore, a large part of our job consisted in describing signaling protocols to other components so they could perform their services.
The core components of the system worked by calling each other through function interfaces. However, several of the components, such as Billing, Directory, and Management, also depended on message passing schemes. These systems basically followed the signaling protocol and intercepted messages on what we called the Message Centers. These Message Centers were communication packages that ran on each host. They allowed registered listeners to tap incoming and outgoing traffic. This allowed components like Billing and Management to become pluggable. The Signaling group only had to start us up, after that we would become completely transparent to the system. We got our information from the initiation and accept messages that entered and exited hosts. For example we would start tracking ongoing calls when the final accept messages came from the Signaling Server.
We managed to establish interfaces that each team was to use for their own development early on in the semester. We also began the system design with the core groups, which helped us understand the system so we could design our Network Administration application. We spent our time meeting with each group from time to time, to make sure that interfaces remained consistent and that work progressed.
The MIA Network Management Application design was supposed to fulfill the requirements of a passive observer, and also perform some critical services for the system. Although management usually runs transparently to the rest of the system, management is allowed to send certain messages to system components. We can set parameters for the Gateway and Data Exchange, and we perform failure detection on all the hosts of the system.
The architecture of the system was as defined in the Third Report (Presented here with some modifications).
The system definition is in its final state and implementation of the final-cut is finished.
The final system.
The system consists of 2 parts CMS (Central Management Server) and MC (Management Children). We have one CMS, and 5 different kinds of MC’s: MC_Signal, MC_Gateway, MC_Directory, MC_Billing, MC_App (There is only one MC_App definition for all the Apps).
CMS (Central Management Server):
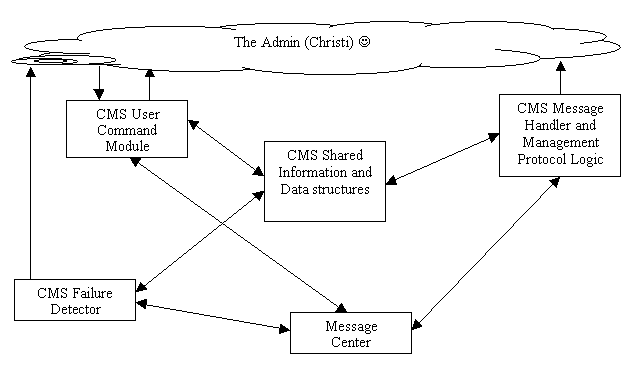
The CMS User Command module is basically a thread which supports user level commands such as "set", which is used to either query all the params, or set a variety of parameters, such as 3 types of Data Exchange Parameters, 2 types of gateway parameters, and 3 types of failure detector parameters.
The CMS Message Handler is the main event handler where the CMS protocol runs. Here we receive new host messages, connection start, and connection end messages, host shutdown messages, gateway usage change messages, and heartbeat messages.
The CMS Failure Detector is a heartbeat detector thread, which goes through a list of all the active hosts (including Signaling Server, Directory Server, Billing Server, Gateway, and all the up Apps), and sees if we have received a heartbeat from each. The algorithm here is similar to a second-chance clock algorithm, which takes appropriate actions after a particular host misses several heartbeats. If an App misses several heartbeats, we send a message to Signaling, Billing, Directory, and all the active Applications, telling them to Garbage Collect information related to the crashed host. We also notify the user of these events as well. In special cases such as a directory and billing server crash, the Failure Detector tries to search for a Secondary Server to failover to.
The Shared Information Structure is the primary database of the CMS, it is here that all information related to active hosts, ongoing calls, hosts status, is kept.
MC (Management Child):
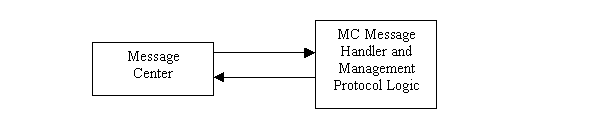
The MC_Signal child runs on the main Signal Server. The CMS, when it first boots up, asks the user for the address of the signaling server, and then contacts the MC_Signal child. The MC_Signal child then forwards this information to all the MC_ children after their respective Servers or Apps start up. This child is also responsible for telling the CMS about Multi-party setup and teardown events. It also maintains a heartbeat with the CMS. This child also tells CMS about clients leaving from a multi-party group.
The MC_Gateway child runs on the Gateway, and its job is make parameter adjustment calls into the Gateway code, and send notification to the CMS which of the Gateway’s two wires is currently in use. This also maintains a heartbeat with the CMS.
The MC_Directory child runs on the main directory server and notifies CMS of lookup or addition events that happen at the main directory server (it does this by snooping on the directory server’s message center). It also maintains a heartbeat with the CMS. It also notifies CMS about illegal directory accesses made by rogue users (this is done through a message passing between directory server and the MC_Directory child).
The MC_Billing child performs almost the same functions as the MC_Directory child, however the MC_Billing child does not notify the CMS about security breaches on the Billing Server.
The MC_App children are responsible to notifies the CMS of 2-party call setup and teardown. They also notify CMS of a multi-party group creation, and multi-party group join. They also maintain Heartbeats with the CMS.
Our MC’s and CMS conform to Signal’s Multi-Party and Two-Party call-setup and teardown protocols. We always trigger a CMS update on the final accept for each case. Since Signals implements a 3-way handshake for all call setups, we trigger our CMS update on the 3rd handshake.
The decision to insert failure detection was our idea, since after completion of system design we realized, that Signals did not maintain active heartbeats with their client hosts. Therefore, since we maintained data structures based on the signaling protocol, we also wanted to garbage collect information, in case calls did not get torn down gracefully. So, to solve this problem we had to implement our Failure Detection system. Furthermore, we could forward this information to Billing, Directory, and Signals so that they could clean up their data structures as well.
We also designed a traffic generator for the MC's which we called TestMC. This was used to send simulated message traffic to independently running MC's, and see whether the MC to CMS protocol actually worked.
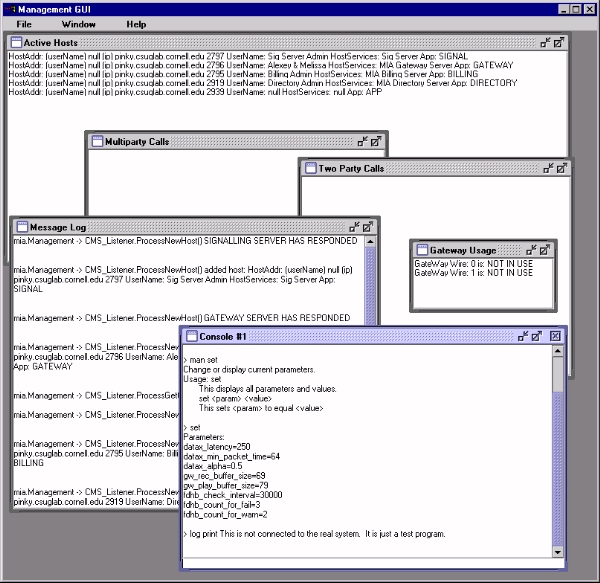
Screenshot of our Network Management application user interface.
3. Problems: (1-2 pages) It is possible that you did not actually accomplish what you set out to do :-( If so, why? What problems did you run into? Include both technical problems, and problems in coordinating your work with others. Be as specific as you can about technical problems. This is the only way we have to determine whether you really tried to solve the problem, instead of just giving up with token effort.
We actually did not get to accomplish what we had set out to do. We had wanted to get the system fully integrated and running by study week, however, the integration happened a few days before the demo. There were several causes for this, several teams did not start developing their applications until late. Although several components started their work really early, due to other project courses, they did not manage to finish their coding in time. Ultimately, although coding was supposedly finished, a large amount of debugging ended up happening during the final week of the semester to get the system functioning to a reasonable level.
We found that there was a limit to what we could get people to do, and for us that limit was that we would not write the code for them. Many times, we would explain a protocol several times to a given component (i.e. how to use the Signaling Server to capture information about where the component’s main server was running, in this case the component’s main server had already registered with the main Signaling Server). However, it would turn out that repeatedly people would not implement these simple things until the very end, and then they would ask us again how the protocol exactly worked.
Although, thankfully, no one made a critical change to the interfaces near the end of the project, the actual integration happened so late that the Apps barely got a chance to run their code on the actual system. This was the case, because the core was not finished in time for the Apps to test. The fact that interfaces were consistent was no help when the core system was not finished.
Most of these problems arose not out of laziness, or reluctance to work, as most of the people in our group were rather hard workers. These problems arose because most of us were Seniors, MEngs, and Juniors, who were taking at least one if not two or more project courses along with this one, and most of us had no idea of the enormous magnitude of this project during the beginning stages.
The final item that we did not get to accomplish in our agenda, was to make the CMS (Central Management Server) Highly-Available. Since, we are the only component that does failure detection of all the hosts in the system, we can be considered a single point of failure. Therefore, to solve this problem, we wanted to have a group of CMS servers, which would have talked to each other using a Reliable Group Membership Protocol (RGMP), such as the Ensemble system designed at Cornell. Only one server would have been the point of communication to the MC’s. I.e. one of the servers would have handled MC communication until it crashed, if this happened the other servers would detect the crash through the Reliable Group Membership Protocol, and then the next server in line would start up using the IP and port of the crashed server. This would allow the MC to communicate to the same CMS address as before. There were two problems that would have needed further solutions. First, the state of the backup CMS’s would have to be updated appropriately (i.e. any state change made to the Primary CMS would have to be reliably broadcast to the backup CMS’s using the Reliable Group Membership Protocol). Second, during Primary CMS crash, the next backup in line would have to assume the Primary’s IP address. We could have simulated this by running all the CMS’s on the same machine, and crashing individual server applications instead of crashing the machine.
4. What you learnt: (1-2 pages) What did you learn by working on the project? Include details on technical things you learnt, as well as what you learnt about dealing with large projects, collaborating with other busy people, and dealing with other coursework.
While working on this project we learned several critical things. First and foremost we learned that we must never take more than two project courses at the same time (especially the Masters level courses). Our learning experience can be divided into two parts, technical and group management.
Work on this project definitely taught us a lot of new things, which we had not been exposed to. We had never used cvs for source code control (we were used to Visual Source Safe). The late night struggling with cvs taught us a new appreciation for code maintenance in large projects. Another, problem that we had to deal with was building large pieces of code. If people do not use the same compilers, and some people use IDE’s (Integrated Developer Environment) while others simply use directories, the job to rebuild someone else’s code to run becomes quite a task. Furthermore, this project gave us a heightened appreciation of the idiosyncrasies of the different Java compiler specifications, which lead to a myriad of wonderful compatibility problems.
From a group manager’s perspective, we realized that it is essentially impossible to manage a group of 18 people, when none of them have a matching schedule. Second, the best way to be able to help the team is to understand the system under development. If we understand the system then we can answer any team’s questions, or at least direct them to the appropriate people who can provide a more detailed answer to the question.
5. What would you do differently next time: (1-2 pages) Everyone makes mistakes. But good learners don't repeat mistakes, they make all new ones! This project gave you a lot of freedom to make mistakes. What will you look out for the next time you undertake a large collaborative project?
If we were to do this a second time, we would probably try to coordinate code revisions a bit better. Even the tiniest inconsistencies could cause compatibility problems. During integration, there were a couple instances of errors being caused by using slightly different versions of files. This is especially troublesome with the short time slots allotted on Vada, as we lost some time looking for relatively simple errors (as opposed to the much more insidious ones).
Another thing we should have done was to get basic, "no frills" implementations working earlier. These would have made it easier for the different teams to test their code. Instead, some of the teams wrote their own test classes in addition to trying completing their own tasks. We also would have tried to keep groups in better synch with each other. The problem was that the different groups all worked in different locations. They obviously could not all work on the single machine that was allotted to the group at the same time. Next time, we would arrange for a common work place to facilitate better communication between the different teams.
We would also try to arrange for more whole-group meetings. This would be the easiest way for problems and to be discussed and consensus to be reached. The more “personal schedule friendly” approach we took was not the most efficient way of discussing problems, as sometimes we had to repeat the same information several times due to scheduling conflicts. Full group meetings would also have the advantage of providing more immediate feedback to questions, comments, and suggestions. The difficulty arose mainly from the heavy amount of time needed for other courses, job interviews, etc. Finding a common time that most people could attend was next to impossible.
Finally, a more rigorous schedule would be enforced. We did not have quite as much time for integration as we would have liked, since we fell slightly behind schedule toward the end. It is more important to complete the main goals than it is to add minor, non-critical features.
6. Interface that your team will provide to other teams or use: Please give the exact procedure calls that you will make or support. This is your final interface spec. /C++/Java code is OK.
Interfaces Used
From Gateway:
parameters: record buffer size, play buffer size
gw_get_param(int ParameterId);
gw_set_param(int ParameterId, int ParameterValue);
From Data Exchange:
parameters: latency, min packet time, "alpha"
From Signaling:
Messages:
ResponseMessage - in response to Multi-Party join confirmation, and in response to a Two-party handshake completion.
CreateGroupMessage - used to detect new Multi-Party Group formation
GoodByeMessage - when a Two-Party call is torn down, or when a host leaves a Multi-Party group.
HelloMessage - used to detect a new host
SetupConnectionMessage - used to detect a new connection being setup through a gateway
TeardownConnectionMessage - used to detect an end of a call through the gateway
From Directory:
Messages:
IllegalRequestMessage - used to detect an illegal access of the Directory Service
InitInfoMessage - used to detect a new Directory Server
From Billing:
Messages:
BS_HelloClientOnSignal - used to detect a new Billing Server
Interfaces Provided
To Signalling:
Message:
CMS_MsgDataXParams - used to set the Data Exchange parameters
To Signaling, Billing & Directory:
Message:
CMS_MsgGarbageCollectHost - used to notify all the existing hosts, about a crashed host
7. Advice for the course staff: What mistakes did we make in running this project? Please help us improve the course.
This project is too large. Most people in our group will not have any time to study for the final exam. Also, most members of our group have more than one major project course (cs514, cs432/433, etc.), which limits the time we can spend on the project and the individual puzzles. Other than that, the only real problem was in the availability of the equipment. Besides the five group computers, only two other computers in the room had sound card drivers installed. We had to go to the other rooms to test. Also, more than one machine with a dialogic card would have been very helpful, as the groups would not have to vie for gateway time. In general, we would like the lab machines to be set up correctly in the future in the CSUGLAB. All the machines in the CSUGLAB have sound cards, but very few of them have been set up by the admins to use the sound cards.
8. References: What sources did you consult in working out the details of your project? URLs for Web pages are acceptable for references.
http://java.sun.com/
MIA Teams: Signals, Gateway, DataX, Directory, Billing, WhitePages, VoiceEmail, On line Lecture Service, WhiteBoard & Conferencing.