Lecturer: Tom Roeder
Lecture notes by
Tom Roeder
A major goal of cryptography ("hidden writing") is to define and construct operations that write, read, and attest to information using secrets in a way so that principals that do not know the secrets cannot perform the operations. Constructing such operations requires us to come up with functions that are hard to compute, so that, e.g., reading hidden information is hard, or coming up with a signature on a new document is hard. Two examples illustrate these problems in real life.
The first example involves signatures. Each time we write a check or sign a contract or a letter, we create a handwritten signature that supposedly attests to us having marked a document as coming from us. We will say that the signature provides authentication for the document. Of course, as everyone who's ever attended grade school knows, handwritten signatures can be forged, even by industrious children (a fairly weak threat model). Worse, the signature doesn't say anything about the document for which it purports to provide authentication; in fact, it is expected to be the same for every document (banks and other institutions often rely on this property), so carbon paper or scanning technology allows us to sign anything for an principal once we've seen a single instance of that principal's signature. So, the guarantees of handwritten signatures are not very strong; we need similar but stronger attestation functionality for security in real systems.
A better signature scheme would require that a signature for a given document uniquely refer to that document's contents and that it be hard to produce a signature for a given principal except by that principal. In this case, the hard operation is constructing a signature for a document given any number of signatures on other documents.
The second example involves passing secret messages. Many properties that we want from everyday actions can be achieved by operations that hide information. For instance, when the CS 513 staff returns your homework, you might want it to be the case that no-one knows the grade you got. This property is often guaranteed by course management systems like CMS, but we could just post grades in the hallway under some transformation if we could guarantee that it would not reveal the binding from grade to student. Similarly, when you send an email to the course instructor complaining about this lecture or about my bias in grading your homework, you would prefer that I not be able to read the message, even if I have full control of the network along which your message will pass. Even better, you'd really like me not to know anything more than the fact that you sent a message to the instructor (you might not even want me to know that you sent a message, but this is a stronger property than we will discuss in these introductory lectures). A good encryption scheme solves these problems; it allows principals to pass information that only a given principal can read.
Both of the above examples relied on the existence of functions that are easy to compute in some contexts but hard to compute in others. Of course, the notion of "hardness" depends entirely on the threat model. If an adversary has unlimited computational resources, then defending against attacks becomes much more difficult. The notion of computational resources is fundamental in cryptography; we can think of it as the size of and number of computers available to an attacker.
It might be reasonable for you to suppose that other students in CS 513 that are trying to figure out what grade you got only have access to, say, the computers in the MEng lab; on the other hand, when the USA and Russia sign a treaty on nuclear weapons, each side should, in principle, not assume anything at all about how many or how powerful computers the other side has. In such contexts, the safest assumption is that the adversary has unlimited computational resources; think of this as having a computer that can perform an arbitrary number of operations instantly. Amazingly, some functions for encryption and authentication can be found that defend against attacks by adversaries with unlimited computing power, though operations using these functions are normally far less efficient than ones that satisfy weaker properties. Such defenses always depend on the ability of hosts to choose random numbers.
In this course, we will almost always consider defending against adversaries that only have a limited amount of computing power. Usually we say that such adversaries can do an amount of computation that is polynomial (as opposed to exponential) in some security parameter; this parameter also controls the amount of work principals must do to perform the given operation. Under this model, the kind of functions we call computationally hard will be hard to compute except for a very small probability. Unless the adversary makes a lucky guess (which is exponentially unlikely in that same security parameter), their computation will not produce the right answers.
We also limit the adversary as to what actions it can perform in the network: a common model in this domain was proposed by Danny Dolev and Andrew Yao in the early '80s, so it is called the Dolev-Yao model. Dolev-Yao treats computationally hard functions as perfect (having no probability of of being computed): reconciling these two views is a topic of current research, but the results are generally encouraging; much of cryptography can be treated as perfect in many common settings. Dolev-Yao allows adversaries to:
Notice that this threat model allows adversaries to completely control communication channels: any message can be blocked by redirecting it to a principal under the control of the adversary. Note that these assumptions are weaker than the Fair Links assumption in distributed systems (the adversary has more abilities, so we are making weaker assumptions about the adversary), which simply asserts that if an infinite number of messages have been sent, then an infinite number of messages will be received. Under Dolev-Yao, there is no such guarantee.
In many contexts, the Dolev-Yao model is stronger than real-life adversaries. For instance, some online auction or exchange sites suffer from requests from fraudulent purchasers; these sites have been known to prepend warnings to emails sent via internal emailing mechanisms. But if adversaries control the network and can modify any message on it, then these prepended warnings could easily be erased. Since these prepended warnings are normally received even on fraudulent emails, it is clear that this real-life adversary model is weaker than Dolev-Yao.
Solutions to the signature problem fundamentally depend on principals being able to compute something that no one else can compute, but everyone else can check was computed correctly for that principal. For instance, consider a stock broker receiving messages from a client; the broker would like to be able to prove that actions he takes are exactly those requested by the client. To this end, the client publishes a public pair of messages M1 and M2, which correspond to buy and sell for a particular stock for a particular amount (generalizing similar schemes to multiple messages and multiple prices is left as an exercise). The broker can then recognize either message if sent by the client. But when the client sends Mi, the broker has no way of proving that the client requested the action associated with Mi, since the client could always have claimed to send the other message and, in fact, anyone could have sent the message.
Suppose, however, that the client generates M1 and M2 as follows: it chooses two random messages m1 and m2 and computes M1 = f(m1) and M2 = f(m2) for some agreed-upon function f. Then, when the client wants to send message M2, it sends m2 to the broker, who confirms that M2 = f(m2). The broker, if challenged, can produce mi to show that the client requested the action corresponding to Mi. Obviously, several assumptions are needed to make this scheme work. Note, for instance, that if f is the identity function, then this scheme is no different than the original.
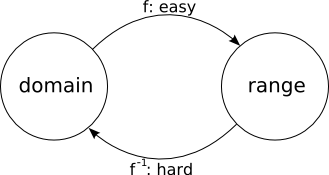
One important assumption for this scheme to work is that it is hard to find m1 or m2 given M1, M2, and f (for instance, if f is the identity function f(x) = x, then this scheme has no more security than the original). Such a function is called a one-way function (OWF). Intuitively, it is easy to compute the function, but hard to compute its inverse.
One-way functions require that, given a random x and y = f(x), it is computationally hard to find an x' (maybe equal to x) such that f(x') = y.
Most of cryptography is based (sometimes rather indirectly) on the existence of one-way functions; unfortunately, one-way functions are not known to exist, though it is known that if one-way functions exist, then P is not equal to NP.
One-way functions do not guarantee that all properties of the input are hidden by the output. In fact, adversaries may be able to learn some significant information about the input, but not enough to find an x' efficiently. For example, a function f might be constructed that mapped all even numbers to another even number and all odd numbers to another odd number. In this case, f could be constructed to be a one-way function even though it reveals the first bit of its input.
Solutions to the encryption problem fundamentally depend on being able to produce output that looks random; think about the requirements we stated above:
It is not intuitively clear how to use one-way functions to satisfy these requirements, since one-way functions are allowed to leak some information about their input. The idea behind no-one knowing anything more than the fact that you sent a message to the instructor is that they can't distinguish what you sent from a random message.
This is all fine and well, but what does it mean for something to look random? The intuition behind the formal definition is that a sequence b1, b2, ..., bn of single bits looks random if it is computationally hard to predict the next value bn+1 in that sequence with probability much better than 1/2. This test is called the Next Bit Test, and it can be shown to be the strongest test for randomness of unbiased sources.
Pseudo-random functions (PRF) take a key and a value as input and output a value that looks random to principals that do not know the key. More formally, it is hard on average to distinguish the output of a pseudo-random function from the output of a random function. To principals that do know the key, the Next Bit Test fails; any principal with the key can, by definition of a PRF, generate the next bit efficiently.