Let's look at the time complexity of -NN.
Suppose we are in a -dimensional space, and we have trained on data points.
With the naive -NN setup we saw earlier in the semester, our learned "model" is just a memorization of all the points in the training set,
so our time complexity for training is , since we need to copy the whole training set.
When testing, we need to compute the distance between our new data point and all of the data points we trained on.
Classifying one test input is also , since we need to pass through the whole saved training set to compute the distances.
To achieve the best accuracy we can, we would like our training data set to be very large (), but this will become a serious bottleneck during test time.
Previously, we looked at a lot of linear-model-based machine learning methods that avoid this problem by having a
parameterized hypothesis class with fixed parameter dimension (i.e. ) such that
predictions take time to make. But we also saw that this can limit the models we learn. Sometimes, we really
want -NN behavior—not a linear model or even a kernel model—but we also want it to scale nicely to large
datasets.
Goal: Can we make k-NN faster during testing?
We can do it—if we use clever data structures.
A thought experiment
Suppose I want to do 7-NN on a large dataset that is split up into two roughly-equally-sized portions, each possessed by one of my colleagues Alice and Bob. That is, .
One way I can do this is the following.
Given a test point , I ask Alice to run 7-NN for on her dataset. Then I ask Bob to run 7-NN for on his dataset. Then I find the seven nearest neighbors from among the fourteen returned by Alice and Bob.
Now, suppose that the 7th-nearest neighbor returned by Alice is at a distance 1 from . And when I look at the closest neighbor returned by Bob, I see it's at a distance 3 from . Do I even need to evaluate the other neighbors returned by Bob? No! They're all going to be further away than Alice's neighbors.
Imagine that Alice and Bob have their datasets stored such that sometimes they can give me a lower bound on the distance from to its nearest neighbor in their dataset—in much less time than it would require to run the full -NN search. Then a sequence of events like the following could occur:
Given , I ask Alice for a lower-bound on its distance-to-nearest-neighbor in her dataset. Alice outputs 0, a trivial lower bound.
I ask Bob for a lower-bound on 's distance-to-nearest-neighbor in his dataset. Bob outputs 2, a non-trivial lower bound.
I ask Alice to run 7-NN for on her dataset. Alice outputs 7 points, where the furthest one away from is at a distance 1.
I don't need to ask Bob to run 7-NN on his dataset, since I know Alice's neighbors are all going to be closer than anything in Bob's dataset.
Compared with the naive algorithm, I've saved the compute cost of processing Bob's dataset. This ability to save work with a lower bound on the distance to a set of points is what underlies the KD-tree datastructure.
k-Dimensional Trees
The general idea of KD-trees is to partition the feature space and search it cleverly rather than by brute force.
Those of you who have taken CS4/5700 may recognize these ideas we're about to cover as similar to those used in
search algorithms in AI, such as A* search.
The plan is to create a data structure that enables us to "discard" (i.e. rule out as being one of the nearest neighbors) lots of data points in a single step because we can prove they are all further away than some points we've already found.
We partition the following way:
Divide your data into two halves, e.g. left and right, along one feature.
For each training input, remember the half it lies in.
How can this partitioning speed up testing? Let's think about it for the 1-NN case.
Identify which side the test point lies in, e.g. the right side.
Find the nearest neighbor of in the same side. The denotes that our nearest neighbor is also on the right side.
Compute the distance between and the dividing "wall". Denote this as .
If you are done, and we get a 2x speedup.
Otherwise, we need to proceed to search the left-side partition.
Fig: Partitioning the feature space.
In other words: if the distance to the partition is larger than the distance to our closest neighbor, we know that none of the data points inside that partition can be closer.
We can avoid computing the distance to any of the points in that entire partition.
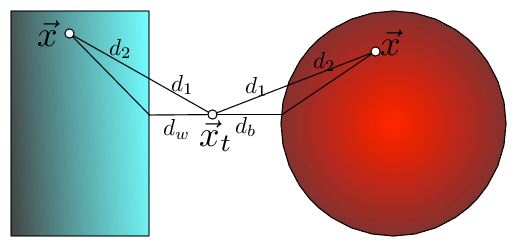
We can prove this formally with the triangle inequality. (See Figure 2 for an illustration.)
Let denote the distance between our test point and a candidate . We know that lies on the other side of the wall, so this distance is dissected into two parts , where is the part of the distance on side of the wall and is the part of the distance on side of the wall. Also let denote the shortest distance from to the wall. We know that and therefore it follows that
This implies that if is already larger than the distance to the current best candidate point for the nearest neighbor, we can safely discard as a candidate.
Fig 2: The bounding of the distance between and with KD-trees and Ball trees (here is drawn twice, once for each setting). The distance can be dissected into two components , where is the outside ball/box component and the component inside the ball/box. In both cases can be lower bounded by the distance to the wall, , or ball, , respectively i.e. .
Quiz: Construct a case where this does not work.
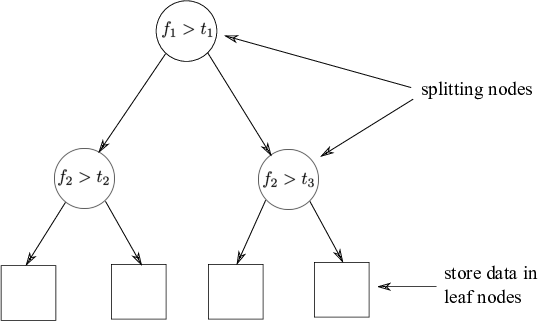
KD-tree data structure
Fig: The partitioned feature space with corresponding KD-tree.
Tree Construction:
Split data recursively in half on exactly one feature.
Rotate through features.
When rotating through features, a good heuristic is to pick the feature with maximum variance.
Example:
Which partitions can be pruned?
Which must be searched and in what order? Pros:
Exact.
Easy to build.
Cons:
Curse of Dimensionality makes KD-Trees ineffective for higher number of dimensions.
All splits are axis aligned.
Approximation: Limit search to leafs only.
Ball-trees
Similar to KD-trees, but instead of boxes use hyper-spheres (balls). (See Figure 2 for an illustration.)
As before we can dissect the distance and use the triangular inequality
If the distance to the ball, , is larger than distance to the currently closest neighbor, we can safely ignore the ball and all points within.
The ball structure allows us to partition the data along an underlying manifold that our points are on, instead of repeatedly dissecting the entire feature space (as in KD-Trees).
Ball-tree Construction
Input: set , ,
Note: Steps 3 & 4 pick the direction with a large spread ()
Ball-Tree Use
Same as KD-Trees
Slower than KD-Trees in low dimensions () but a lot faster in high dimensions. Both are affected by the curse of dimensionality, but Ball-trees tend to still work if data exhibits local structure (e.g. lies on a low-dimensional manifold).
Summary
-NN is slow during testing because it does a lot of unecessary work.
KD-trees partition the feature space so we can rule out whole partitions that are further away than our closest neighbors. However, the splits are axis aligned which does not extend well to higher dimensions.
Ball-trees partition the manifold the points are on, as opposed to the whole space. This allows it to perform much better in higher dimensions.