In words, we assume that the data is drawn from a "line" through the origin (one can always add a bias / offset
through an additional dimension, similar to the
Perceptron). For each data point with
features , the label is drawn from a Gaussian with
mean and variance . Our task
is to estimate the slope from the data.
Estimating with MLE
We are minimizing a loss function, . This
particular loss function is also known as the squared loss or Ordinary
Least Squares (OLS). In this form, it has a natural interpretation as the average
squared error of the prediction over the training set.
OLS can be optimized with gradient descent, Newton's
method, or in closed form.
Closed Form Solution: if is invertible, then
Otherwise, there is not a unique solution, and any that is a solution of the linear equation
minimizes the objective.
Estimating with MAP
To use MAP, we will need to make an additional modeling assumption of a prior
for the weight .
With this, our MAP estimator becomes
This objective is known as Ridge Regression. It has a closed form solution
of: where
and
.
The solution must always exist and be unique (why?).
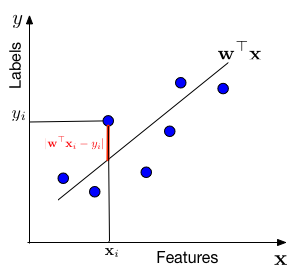 Data Assumption:
Data Assumption: