is the bias term (without the bias term, the hyperplane that defines would always have to go through the origin).
Dealing with can be a pain, so we 'absorb' it into the feature vector by adding one additional constant dimension.
Under this convention,
We can verify that
Using this, we can simplify the above formulation of to
(Left:) The original data is 1-dimensional (top row) or 2-dimensional (bottom row). There is no hyper-plane that passes through the origin and separates the red and blue points. (Right:) After a constant dimension was added to all data points such a hyperplane exists.
Observation: Note that
where 'classified correctly' means that is on the correct side of the hyperplane defined by .
Also, note that the left side depends on (it wouldn't work if, for example ).
Perceptron Algorithm
Now that we know what the is supposed to do (defining a hyperplane the separates the data), let's look at how we can get such .
Perceptron Algorithm
Geometric Intuition
Illustration of a Perceptron update. (Left:) The hyperplane defined by misclassifies one red (-1) and one blue (+1) point. (Middle:) The red point is chosen and used for an update. Because its label is -1 we need to subtract from . (Right:) The udpated hyperplane separates the two classes and the Perceptron algorithm has converged.
Quiz: Assume a data set consists only of a single data point . How often can a Perceptron misclassify this point repeatedly? What if the initial weight vector was initialized randomly and not as the all-zero vector?
Perceptron Convergence
The Perceptron was arguably the first algorithm with a strong formal guarantee. If a data set is linearly separable, the Perceptron will find a separating hyperplane in a finite number of updates. (If the data is not linearly separable, it will loop forever.)
The argument goes as follows:
Suppose such that .
Now, suppose that we rescale each data point and the such that
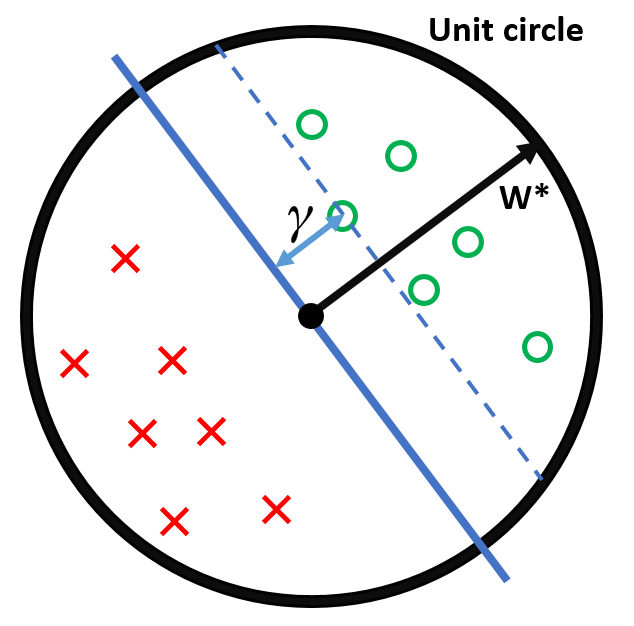
Let us define the Margin of the hyperplane as
.
A little observation (which will come in very handy): For all we must have . Why? Because is a perfect classifier, so all training data points lie on the "correct" side of the hyper-plane and therefore . The second inequality follows directly from the definition of the margin .
To summarize our setup:
All inputs live within the unit sphere
There exists a separating hyperplane defined by , with (i.e. lies exactly on the unit sphere).
is the distance from this hyperplane (blue) to the closest data point.
Theorem: If all of the above holds, then the Perceptron algorithm makes at most mistakes.
Proof:
Keeping what we defined above, consider the effect of an update ( becomes ) on the two terms and .
We will use two facts:
: This holds because is misclassified by - otherwise we wouldn't make the update.
: This holds because is a separating hyper-plane and classifies all points correctly.
Consider the effect of an update on :
The inequality follows from the fact that, for , the distance from the hyperplane defined by to must be at least (i.e. ).
This means that for each update,grows by at least.
Consider the effect of an update on :
The inequality follows from the fact that
as we had to make an update, meaning was misclassified
as and all (because ).
This means that for each update,grows by at most 1.
Now remember from the Perceptron algorithm that we initialize . Hence, initially and and after updates the following two inequalities must hold:
(1)
(2) .
We can then complete the proof:
Quiz: Given the theorem above, what can you say about the margin of a classifier (what is more desirable, a large margin or a small margin?) Can you characterize data sets for which the Perceptron algorithm will converge quickly? Draw an example.