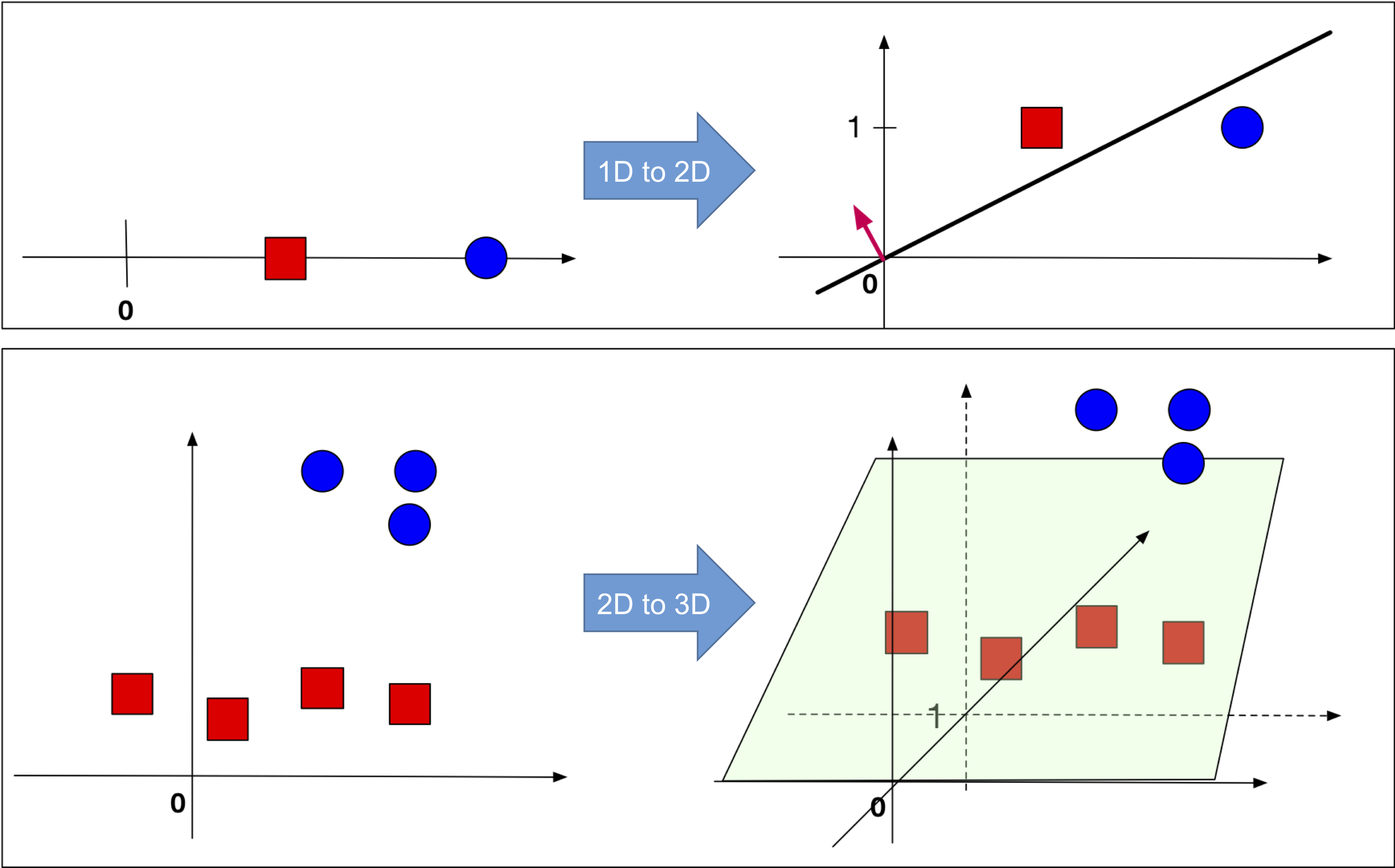
| Illustration of a Perceptron update. (Left:) The hyperplane defined by wt misclassifies one red (-1) and one blue (+1) point. (Middle:) The red point x is chosen and used for an update. Because its label is -1 we need to subtract x from wt. (Right:) The udpated hyperplane wt+1=wt−x separates the two classes and the Perceptron algorithm has converged. |