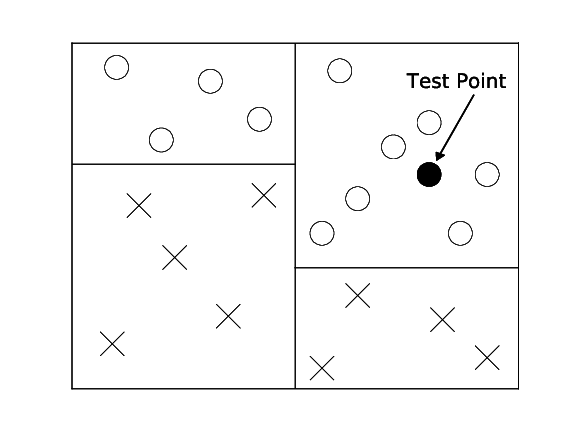
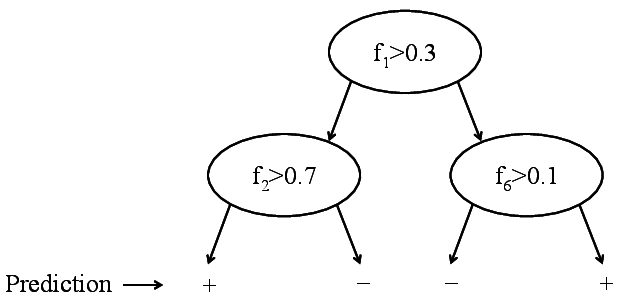
Often you don't care about the exact nearest neighbor, you just want to make a prediction.
Nearest neighbor search is slow and requires a lot of storage O(nd).
New idea:
Build a KD-type tree with only pure leaves
Descent test point and make decision based on leaf label. Exact nearest neighbor is not really needed.
Binary decision tree. Only labels are stored.
New goal: Build a tree that is:
Maximally compact
Only has pure leaves
Quiz: Is it always possible to find a consistent tree?
Yes, if and only if no two input vectors have identical features but different labels
Bad News! Finding a minimum size tree is NP-Hard!! Good News: We can approximate it very effectively with a greedy strategy.
We keep splitting the data to minimize an impurity function that measures label purity amongst the children.
Impurity Functions
Data: S={(x1,y1),…,(xn,yn)},yi∈{1,…,c}, where c is the number of classes
Gini impurity
Let Sk⊆S where Sk={(x,y)∈S:y=k} (all inputs with labels k)
S=S1∪⋯∪Sc Define:
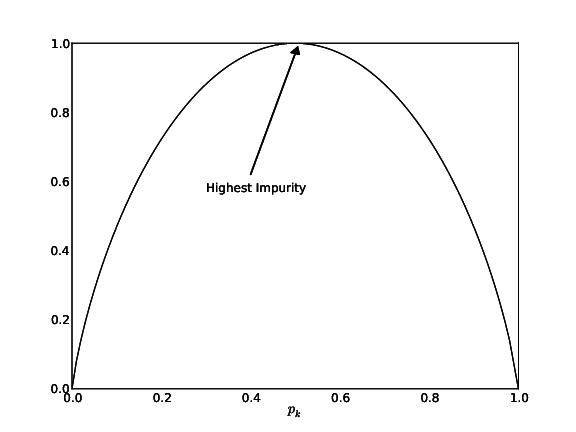
pk=|Sk||S|←fraction of inputs in S with label k Note: This is different from Gini coefficient. See Gini Coefficient of a leaf: G(S)=c∑k=1pk(1−pk)
Fig: Gini Impurity Function
Gini impurity of a tree:
GT(S)=|SL||S|GT(SL)+|SR||S|GT(SR)
where:
(S=SL∪SR)
SL∩SR=∅
|SL||S|←fraction of inputs in left substree
|SR||S|←fraction of inputs in right substree
Entropy
Let p1,…,pk be defined as before.
We know what we don't want (Uniform Distribution): p1=p2=⋯=pc=1c
This is the worst case since each leaf is equally likely. Prediction is random guessing.
Define the impurity as how close we are to uniform. Use KL-Divergence to compute "closeness"
Note: KL-Divergence is not a metric because it is not symmetric, i.e., KL(p||q)≠KL(q||p).
Let q1,…,qc be the uniform label/distribution. i.e. qk=1c∀kKL(p||q)=c∑k=1pklogpkqk≥0←KL-Divergence=∑kpklog(pk)−pklog(qk) where qk=1c=∑kpklog(pk)+pklog(c)=∑kpklog(pk)+log(c)∑kpk where log(c)←constant,∑kpk=1 maxpKL(p||q)=maxp∑kpklog(pk)=minp−∑kpklog(pk)=minp−H(s)←Entropy Entropy over tree:
H(S)=pLH(SL)+pRH(SR)pL=|SL||S|,pR=|SR||S|
ID3-Algorithm
Base Cases:
ID3(S):{if ∃ˉy s.t. ∀(x,y)∈S,y=ˉy⇒return leaf with label ˉyif ∃ˉx s.t. ∀(x,y)∈S,x=ˉx⇒return leaf with mode(y:(x,y)∈S) or mean (regression)
The Equation above indicates the ID3 algorithm stop under two cases. The first case is that all the data points in a subset of have the same label. If this happens, we should stop splitting the subset and create a leaf with label y. The other case is there are no more attributes could be used to split the subset. Then we create a leaf and label it with the most common y.
Try all features and all possible splits. Pick the split that minimizes impurity (e.g. s>t) where f←feature and t←threshold
Recursion:
Define: [SL={(x,y)∈S:xf≤t}SR={(x,y)∈S:xf≥t}] Quiz: Why don't we stop if no split can improve impurity?
Example: XOR
Fig 4: Example XOR
First split does not improve impurity
Decision trees are myopic
Regression Trees
CART: Classification and Regression Trees
Assume labels are continuous: yi∈R Impurity: Squared LossL(S)=1|S|∑(x,y)∈S(y−ˉyS)2←Average squared difference from average labelwhere ˉyS=1|S|∑(x,y)∈Sy←Average label
At leaves, predict ˉyS. Finding best split only costs O(nlogn)
Fig: CART
CART summary:
CART are very light weight classifiers
Very fast during testing
Usually not competitive in accuracy but can become very strong through bagging (Random Forests) and boosting (Gradient Boosted Trees)