Design patterns
Design patterns are coding idioms that help build better programs. The goal is often to help make programs more modular by decoupling communicating code modules. Some design patterns just help avoid mistakes. Design patterns give programmers a common vocabulary for explaining their designs and aid in quick understanding of the advantages and disadvantages of particular designs.
The term design pattern was introduced by the very influential “Gang of Four” book, Design Patterns: Elements of Reusable Object-Oriented Software, by Erich Gamma, Richard Helm, Ralph Johnson, and John Vlissides. The book discusses object-oriented programming and identifies more than 20 design patterns.
Many other design patterns and variations thereof have been identified since, some more useful and meaningful than others. In this lecture we look at some of the more important ones to understand why they are helpful. Understanding patterns will also help you resist the lure of the Cargo Cult Programming antipattern, in which design patterns are used without real purpose.
Iterator pattern
A common problem when designing programs is how to set up a stream of information from a producer module A to a consumer module B, while keeping both A and B decoupled so that each has no dependency on the module they are communicating with. Assuming that the values communicated have some type T, the communication we want can be depicted as follows:
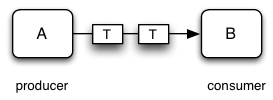
The Iterator design pattern is one way to solve this programming problem. Module A constructs objects that provide the ability for the consumer to “pull” values from the producer. These object provide an interface like the following:
Iterator.java
This is a polling-style interface, in which the consumer can ask any
time for a new object, but might have to wait until something is available.
The next object is retrieved from the Iterator by calling next(). To detect the
end of the iteration without using exceptions, it is standard to use the
hasNext() method.
Once consumer B has obtained an iterator from producer A, it can keep getting new elements from the iterator without mentioning A in any way. The producer code doesn't need know about B, either. Thus, we have complete decoupling of A and B.
An additional advantage of this pattern is that multiple consumers can obtain streams of information from a single producer without interfering with each other. Whatever state is needed to keep track of the position in the stream is stored in the iterator object, not in the producer.
Java provides some convenient syntactic sugar for invoking iterators. A statement of the form
for (T x : c) { ... body ... }
is syntactic sugar for
foreach.java
To use this syntactic sugar, it is necessary that c either be
an array or implement the interface Iterable<T>:
Iterable.java
Implementing iterators
Iterators are very handy and easy for client code to use. They are a welcome addition to interfaces. However, there is one problem: implementing them can be tricky.
The iterator needs to keep track of the current state of the iteration so that it can resume at the right place in the stream on each call to
next(). For tree data structures, tracking iteration state is particularly awkward. The state of the iteration is a path from the root to the current node. This path must be updated on each call tonext.The iterator supports both
hasNext()andnext()methods. ThehasNext()method must figure out whether there is a next element to be provided. Typically, this duplicates work that thenext()might have to do, and in some cases, that work cannot be done separately by the two methods. The iterator must contain additional state to keep track of whether the current answer tohasNext()has been computed yet.-
Dealing with changes to the underlying data structure during iteration is often tricky, so changes to the collection being iterated over is typically forbidden. In the Java collections framework, collection classes throw a
ConcurrentModificationExceptionif an element is requested from an iterator after a mutation to the collection that occurred during the iteration. Note that a concurrent modification can happen even if there is no real concurrency in the system. To detect such requests, every collection class object has a hidden version number that is incremented after each mutation. Iterator objects record the collection's version number when they are created, and compare this version number against the collection's on each call tonext(). A mismatch causes the exception to be thrown.A commonly desired change to the collection is to remove the element currently referenced by the iterator. Iterators may support a
remove()method whose job it is to remove the current element; this operation is not considered a concurrent modification. However, if there are multiple iterators traversing the data structure, aremove()by one iterator will in general break the others.
Generators
Some languages other than Java support another language construct that
makes it easier to implement iterators. The C#, Python, Ruby languages support
generators that send results to the consumer using the
yield statement. An extended version of Java that supports
yield is JMatch, developed at Cornell. In these
languages, one can think of the iterator as running concurrently with the
consumer, but only when the consumer requests a new value. The iterator and
the loop body are coroutines. For example, with
generators, an iterator for trees can be implemented very easily using recursion:
tree_iterator.java
By contrast, a Java implementation of the same iterator will take at least 50 lines of code and offer more opportunities for introducing bugs. On the other hand, a careful Java implementation of a tree iterator can be made to run faster than the generator, by avoiding yielding elements up through every level of the tree. The trick is to keep the path from the root to the current node in a stack.
Ironically, the term iterator originally referred to this style of implementing iteration, which was invented in the language CLU in the 70's. The term generator originally referred to what we now know as the iterator design pattern.
Observer pattern
Sometimes we want to send a stream of information from a producer to a consumer, but it's not convenient to have the consumer polling the producer. Instead, we want to push information from the producer to the consumer. We can think of the information being pushed as events that the consumer wants to know about. This is the idea behind the Observer pattern, which works in the opposite way as the Iterator pattern:

In the Observer pattern, the consumer provides an object implementing the interface
Observer<T>:
Observer.java
Whenever the producer has a new event x to report to the
consumer, it calls the observer's method notify(x). The observer
then does something with the data it receives that is appropriate for the
consumer. Since the observer is provided by the consumer, it knows what
operations the consumer has and is typically inside the consumer's abstraction
boundary, perhaps implemented as an inner class.
How does the producer know which observers to notify? This is accomplished by registering the observer(s) with the producer. The producer implements an interface similar to this:
Observable.java
When the producer receives a call to registerObserver, it records
the observer in its collection of observers to be notified. When the producer
has a new event to provide to consumers, it iterates over the collection,
calling notify on each observer in the collection.
Graphical user interfaces (GUIs) typically involve listeners that listen for keyboard and
mouse events and other events that change the appearance of the display. This is the case with JavaFX, which we will be using in our final project. Such listeners are an instance of the observer pattern.
For example, ActionListeners are observers with a
notify named actionPerformed. If one is setting
up listener l for button clicks, the Observable in question
is the JButton object, and the listener is registered by
calling addActionListener(l).
Like the Iterator pattern, the Observer pattern has the benefit that the producer and consumer can exchange information without tying either implementation to the other. The only information they share is the type of events being listened for. An observable can also provide information to multiple observers simultaneously.
We can see that there is a symmetry to Iterators and Observers. We can
make this a bit more compelling. Using A → B to represent the type of a function
that takes in an A and returns a B, and using () to represent the type of an
empty argument list (which is really the same thing as void), we
have the following types:
Iterator: next: () → T iterator: () → (() → T) Observer: notify: T → () registerObserver: (T → ()) → ()
The types of the Iterator operations are exactly the same as the types of the Observer operations, except that all the arrows are flipped! This shows that we have a duality between Iterator and Observer.
Factory and Abstract Factory patterns
When we create objects using a constructor, we tie the calling code to a particular choice of implementation. For example, when creating a set, we specify exactly which implementation we are using (for simplicity, let's ignore type parameters):
Set s = new HashSet();
One way to avoid binding the client code explicitly to an implementing class is to use factory methods, which we have discussed earlier. We might declare a class with static methods that create appropriate data structures:
class DataStructs {
static Set createSet() { return new HashSet(); }
static Map createMap() { return new HashMap(); }
static List createList() { return new LinkedList(); }
...
}
Now the client can create sets without naming the implementation, and the choice of which implementations to
use for all the data structures has been centralized in the DataStructs class.
Sometimes even static factory methods don't provide enough flexibility. The choice of implementation is still fixed at compile time even if the client code doesn't choose it explicitly. We can solve this problem by using the Abstract Factory pattern. The idea is to define an interface with non-static creator methods for the various kinds of things that need to be allocated.
interface DataStructs {
Set createSet();
Map createMap();
List createList();
...
}
All the choices about what implementation to use can now be bound into an object that
implements this interface. Assuming that object is in a variable ds, the client
might contain:
DataStructs ds; ... Set s = ds.createSet();
Of course the choice of implementation has to be made somewhere, where
ds is initialized, but that can be far away from the uses of
ds, in some other module. Since the abstract factory is an object,
it can be chosen truly dynamically, at run time. There can even be multiple
implementations of an abstract factory interface used within the same program.
One place where the abstract factory approach has been used successfully is for user interface libraries. We might define an interface for creating UI components:
interface UIFactory {
Button createButton(String label);
Label createLabel(String txt);
Scrollbar createScrollbar();
...
}
Then, different UIFactory objects can encapsulate different choices
of look and feel for the user interface, depending on the platform on which they
are running. This is why GUIs look different on Windows and Mac OS.
The implementation of each GUI component is chosen dynamically based on the
underlying OS platform to conform to the look and feel of the platform.
Builder pattern
The Builder pattern is another pattern for object construction. The motivation for this pattern is that often we find ourselves wanting to construct complex objects. Passing all the attributes of the object as part of a constructor call can then lead to many parameters and clunky code that is hard to read. The obvious alternative is to set the attributes of the object using setters, but this approach is even worse, since it leads to a porous abstraction barrier and mistakes result in incompletely initialized objects.
In the Builder pattern, the job of initialization is given to a another class
whose job it is to construct objects. The client passes all the infmration needed
to create the object through a series of method calls to the builder object. A
final call to the builder returns the newly constructed object. This works especially
well for immutable objects, where the object cannot be modified after creation.
The useful class StringBuilder is an example of this pattern. A
StringBuilder builds up a string through a series of append
calls, and a final call to toString() returns the finished string.
For ong strings, this way to construct the string is much more efficient than creating the
string by concatenating many short strings.
Here is another example, in which an EmployeBuilder class makes it
easy to build up an Employee object through a series of cascaded
method calls.
builder.java
A builder class is designed to construct objects of some particular type; it may choose dynamically which particular class to create based on the arguments it is passed, further decoupling the client from the implementing class.
Singleton pattern
Sometimes classes never need to have more than one instance. A class with just one instance is an example of the Singleton pattern. For example, if we wanted a class that represented empty linked lists, we might only allocate a single object of that class, since all empty lists are interchangeable anyway. We can expose it to clients via a public getter, and hide the constructor since it shouldn't be used outside the class itself:
class EmptyList implements List {
private static EmptyList empty = new EmptyList();
private EmptyList() {}
public List empty() { return empty; }
}
The Singleton pattern is also frequently used with the Abstract Factory pattern.
There is no need to have more than one object of the class implementing, say,
DataStructs or UIFactory in the examples above.
Composite
The Composite pattern is a pattern that we've already been using: it refers to using a data structure of objects to provide what appears to the client to be a single object. This idea is simply the combination of data structures with data abstraction. Even common objects like strings are Composite objects in Java.
Interning
A related idea to flyweight objects is interning (known in Lisp as hashconsing). A hash table is used to keep track of all objects of a given class. Object creation is done by a factory method. When a new object is requested to be created, the factory method uses the parameters to the calls to look up whether a suitable object has already been created. If so, this object is returned. Otherwise, a new object is created using the constructor, which is typically made private so the only way to create objects is to go through the factory method. This pattern makes the most sense for immutable abstractions, because it may cause the same objects to be shared across unrelated code or data structures.
Adapter
The Adapter pattern allows an existing object to satisfy an interface it was not originally designed to satisfy, hiding the actual interface provided by the existing object. This is accomplished by using a wrapper object that implements the interface and that simply redirects calls of the new interface to the appropriate calls on the underlying wrapped object.
Decorator
The Decorator pattern is similar to the Adapter pattern. Here the idea is to extend the interface of some existing objects of a class. Unlike in the Adapter pattern, the Decorator interface is a subtype of the interface that the objects already implement; its implementation is a wrapper class that redirects all calls from the original interface to the wrapped object.
External state
Sometimes it is undesirable to record some of the state associated with an object in the object itself, perhaps because the class cannot be extended with new instance variables, because only some of the objects of the class have that extra state, or because that state is involved in an invariant maintained by another module. A second class is defined to contain that external state, and objects of the second class are created as necessary. To allow quickly finding the external state for an object, the external state objects are put into a hash table, using the original object itself as a key to find the state.
Visitor
The Visitor pattern is an important pattern that allows the traversal of a tree data structure (such as an abstract syntax tree) to be factored out from the nodes of the tree in a generic way that can be reused for multiple traversals. There are many variations on the visitor pattern.
Generally when building programs that manipulate abstract syntax tree, such as compilers and interpreters, there is a need for multiple traversals over the abstract syntax tree. For example, a compiler might use AST traversals to perform not only type checking but also other transformations of the AST such as constant folding or translation to a lower-level programming language closer to executable code.
There are two natural ways to organize the code for a set of traversals: as an individual module per traversal or as an individual module per AST type. Object-oriented languages encourage structuring code around types. This structure has the advantage that it is easy to add new types in a modular way, but adding a new traversal involves modifying all of the node types. In procedural and functional languages, it is more natural to structure the code as a set of functions, one per traversal. With this structure, new traversals can be added in a modular way, but adding a new type of nodes to the AST requires modifying all the traversal functions so each knows how to handle the new type.
The Visitor pattern provides a structure to help manage this tension. There are a number of variation on the Visitor pattern, but the common idea is that operations are expressed as subclasses of a common Visitor class. In the classic Visitor pattern, the Visitor class (and its subclasses) have one method for each possible type. The base Visitor class supplies default behavior for the various types, which may be to do nothing or to perform some default traversal of child nodes. Subclasses of Visitor can then override that behavior if desired.
Visitor.java
The classes on which visitors operate supply a method accept(v)
method that invokes the appropriate visitor operation:
Node.java
One variation on the Visitor pattern that is useful for traversing
ASTs is to allow the node types to supply the boilerplate traversal
code. For example, the Node class might provide a method visitChildren()
that invokes k.accept(v) on each child node k.
This refinement allows the boilerplate traversal code to be written just
once and reused to implement multiple traversals.
State machine
Programming in an event-driven style can result in messy designs in which not all events are handled. One way to ensure all events are handled is to think about the program, or about parts of the program, as state machines. Often state machines are presented as mathematical abstractions, but they are also a way to organize code: a design pattern called the state design pattern.
A state machine has a set of states and a set of events that can occur. At any given moment, the machine is in one of the allowed states. However, when it receives a new event, it can change states. For each state and event, there is a new state to which the machine transitions when that event is received in that state. When the number of states is finite, the state machine is sometimes called a finite-state automaton.
As a simple example, consider a window in a graphical user interface. Simplifying a bit, it might be in one of the following states: (opened, closed, fullscreen, minimized). Windows can also have a size and position, but let's ignore that for now. The following events can be received: open, close, minimize, and maximize, corresponding to buttons that can be clicked.
A state machine can be represented as a graph in which the nodes are the states and the edges are the transitions between states. The edges are labeled with the event that causes that transition.
Alternatively, we can specify its behavior by giving a state transition table. The rows of the table correspond to states, and the columns correspond to events. The entries in the table say what the next state is, given the current state and event.
| State | open | close | minimize | maximize |
|---|---|---|---|---|
| 1. opened | — | 2 | 4 | 3 |
| 2. closed | — | — | — | — |
| 3. fullscreen | — | 2 | 4 | — |
| 4. minimized | 1 | — | — | — |
The table helps us think systematically about all the possible things that can happen in the system and be sure we have covered all the possibilities. Thinking about the various entries helps us discover missing event handlers and missing states. For example, when minimizing a maximized window, the state machine above forgets that the window was maximized. When the window is closed and reopened, it will still be minimized. If that is not the desired behavior, we may need to add more states to the state machine.
The entries marked with — represent events that don't make sense in the current state or would not have any effect. These are interesting to think about because sometimes we need to make sure that the user interface doesn't permit those events to happen—perhaps by graying out the corresponding UI component.
In the state design pattern, the various events that can be received by the state machine are represented as different methods on the state machine object. Each method captures one column of the state transition table. This design systematically organizes the code that implements a state machine. The following code suggests how our window example might look in this style.
window.java
Model-View-Controller
Since the GUI components are used to manipulate the information managed by the application, it is tempting to store that information and the algorithms that manipulate it (the application logic) directly in components, perhaps by using inheritance. This is usually a bad idea. The code for graphical presentation of information is different from the underlying operations on that information. Interleaving them makes the code harder to understand and maintain. Moreover, it makes it difficult to port the application to a new platform. For example, you might implement the application in JavaFX and then want to port it to Android, whose GUI toolkit is very different. So it is a good idea to keep GUI code and the application logic separate.
This observation leads to the Model-View-Controller (MVC) pattern, in which the application classes are separated into one of three categories: the model, which contains the important application state and operations, and does not refer to the GUI classes; the view, which provides a graphical view of the model; and the controller, which handles user input and translates it into either changes to the view or commands to be performed on the model.
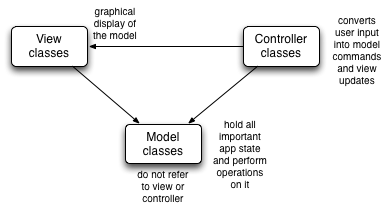
The idea is that the view may hold some state, but only state related to how the model is currently being displayed, or what part of the model is displayed. If the view were destroyed, some version of it could be created anew from the model. With this kind of structure, there can be more than one user interface built on top of the same model. We can even have multiple coexisting views.
One of the challenges of the MVC pattern is how to allow the view to update when the model changes without making the model depend on the view. This task is usually accomplished using the Observer pattern. The model allows observers to be registered on its state; the view is then notified when the state changes.

This separation between model, view, and controller will be very important for Assignment 7, in which you will build a distributed version of the critter simulation. The model will run on a shared server with one or more clients viewing that model through a user interface.
There are many variations of the MVC pattern. Some versions of the MVC pattern make less of a distinction between the view and the controller; this is usually indicated by talking about the M/VC pattern, in which the view and the controller are more tightly coupled, but strong separation is maintained between the model and these two parts of the design.
Antipatterns
There are also coding patterns that are used frequently, but are best avoided. These are often dubbed “antipatterns”. For example, some Java programmers make heavy use of reflection in Java. Using reflection is generally bad practice, leading to slow, fragile code. A good reason to use reflection is if you are loading code dynamically at run time (for example, for plugins or for dynamic code generation). Most applications do not need this capability, so we will not talk much about reflection in this course. A good and rather humorous list of antipatterns can be found on Wikipedia.