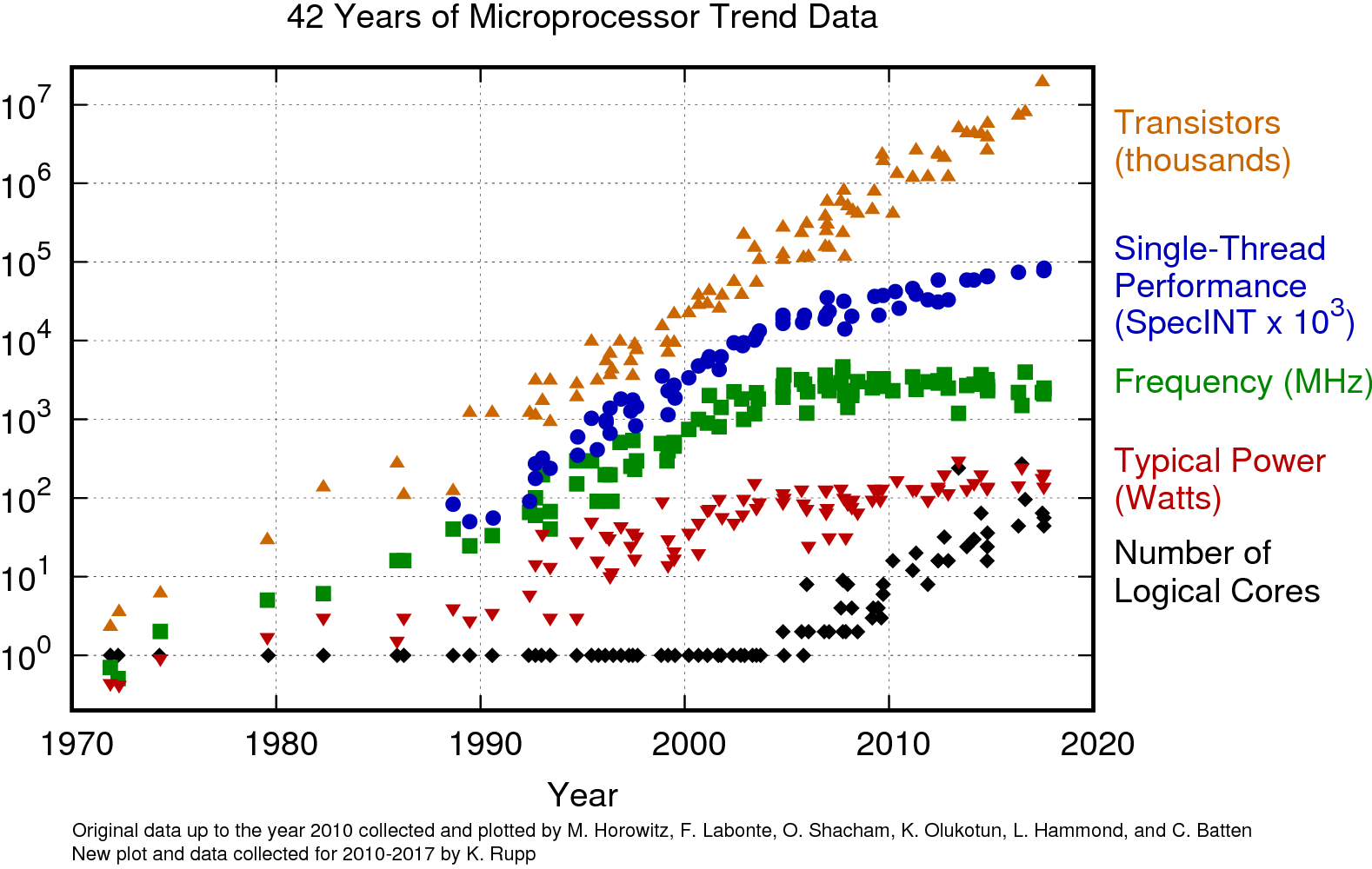
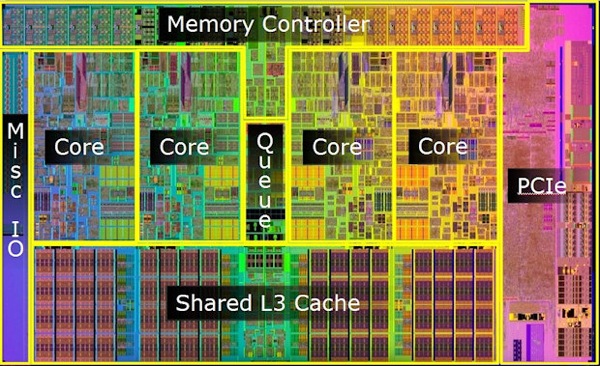
A brief history of computer architecture.¶
For most of the history of computing, CPUs dominated the market for general-purpose computing.

These chips worked by repeatedly performing the following operation:
- Load an instruction from memory.
- According to the instruction, perform some single computation on some data (either in memory or in registers on the chip
- For example, in x86 an
add $10, %eaxinstruction would add the number $10$ to the number currently stored in the integer registereax.
- For example, in x86 an
- Update the instruction pointer to point to the next instuction, or somewhere else if a jump occurred.