Processing math: 100%
Lecture 2: k-nearest neighbors
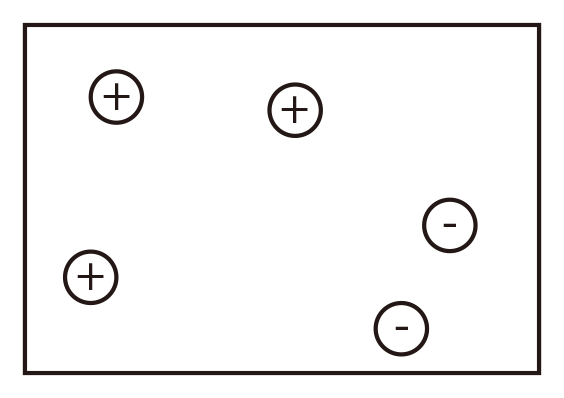
The k-NN algorithm
Assumption:
Similar Inputs have similar outputs
Classification rule:
For a test input x, assign the most common label amongst its k most similar training inputs
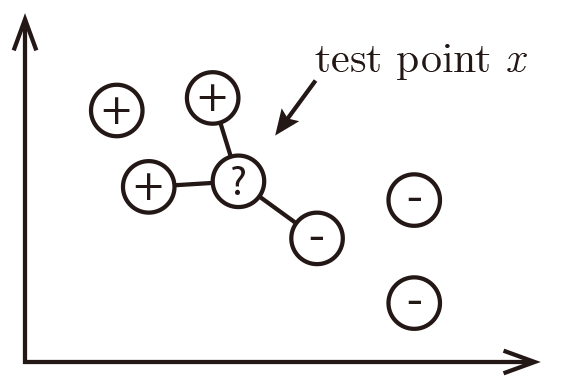 Neighbors' labels are 2×⊕ and 1×⊖ and the result is ⊕.
Neighbors' labels are 2×⊕ and 1×⊖ and the result is ⊕.
Formal (and borderline incomprehensible) definition of k-NN:
Test point: x
Define the set of the k nearest neighbors of x as Sx. Formally Sx is defined as Sx⊆D s.t. |Sx|=k and ∀(x′,y′)∈D∖Sx,
dist(x,x′)≥max(x″,y″)∈Sxdist(x,x″),
(i.e. every point in D but not in Sx is at least as far away from x as the furthest point in Sx).
We can then define the classifier h() as a function returning the most common label in Sx:
h(x)=mode({y″:(x″,y″)∈Sx}),
where mode(⋅) means to select the label of the highest occurrence.
(Hint: In case of a draw, a good solution is to return the result of k-NN with smaller k)
What distance function should we use?
The k-nearest neighbor classifier fundamentally relies on a distance metric. The better that metric reflects label similarity, the better the classified will be. The most common choice is the Minkowski distance
dist(x,z)=(d∑r=1|xr−zr|p)1/p.
Quiz#1: This distance definition is pretty general and contains many well-known distances as special cases:
p=1: Manhattan Distance (l1-norm)
p=2: Euclidean Distance (l2-norm)
p→∞: Maximum Norm
p→0: (not well defined)
Quiz#2: How does k affect the classifier? What happens if k=n? What if k=1?
k=n
k=1
Brief digression (Bayes optimal classifier)
What is the Bayes optimal classifier?
Assume you knew P(y|x). What would you predict?
Examples: y∈{0,1}
P(+1|x)=0.8P(−1|x)=0.2Best prediction: y∗=hopt=argmaxyP(y|x)
(You predict the most likely class.)
What is the error of the BayesOpt classifier?
ϵBayesOpt=1−P(hopt(x)|y)=1−P(y∗|x)
(In our example, that is ϵBayesOpt=0.2.)
You can never do better than the Bayes Optimal Classifier.
1-NN Convergence Proof
Cover and Hart 1967[1]: As n→∞, the 1-NN error is no more than twice the error of the Bayes Optimal classifier.
(Similar guarantees hold for k>1.)
Let xNN be the nearest neighbor of our test point xt. As n→∞, dist(xNN,x)→0,
i.e. xNN→xt.
(This means the nearest neighbor is identical to xt.)
You return the label of xNN.
What is the probability that this is not the label of x?
(This is the probability of drawing two different label of x)
ϵNN=P(y∗|xt)(1−P(y∗|xNN))+P(y∗|xNN)(1−P(y∗|xt))≤(1−P(y∗|xNN)+(1−P(y∗|xt)=2(1−P(y∗|xt)=2ϵBayesOpt,
where the inequality follows from P(y∗|x+)≤1 and P(y∗|xNN)≤1.
 In the limit case, the test point and its nearest neighbor are identical.
There are exactly two cases when a misclassification can occur:
when the test point and its nearest neighbor have different labels.
The probability of this happening is the probability of the two red events:
(1−p(s|x))p(s|x)+p(s|x)(1−p(s|x))=2p(s|x)(1−p(s|x))
In the limit case, the test point and its nearest neighbor are identical.
There are exactly two cases when a misclassification can occur:
when the test point and its nearest neighbor have different labels.
The probability of this happening is the probability of the two red events:
(1−p(s|x))p(s|x)+p(s|x)(1−p(s|x))=2p(s|x)(1−p(s|x))
Good news:
As n→∞, the 1-NN classifier is only a factor 2 worse than the best possible classifier.
Bad news: We are cursed!!
Curse of Dimensionality
Imagine X=[0,1]d, and k=10 and all training data is sampled uniformly
with X, i.e. ∀i,xi∈[0,1]d
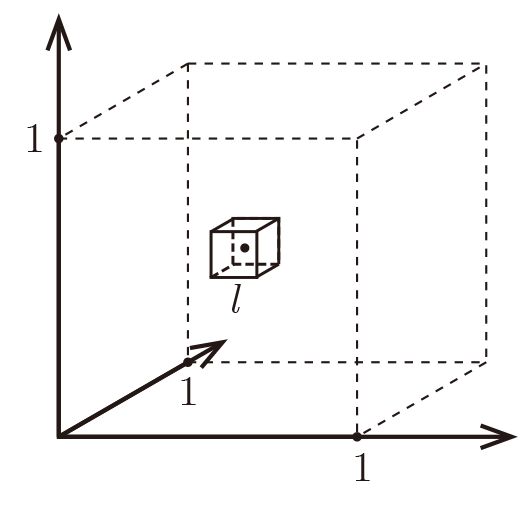
Let ℓ be the edge length of the smallest hyper-cube that contains all k-nearest neighbor of a test point.
Then ℓd≈kn and ℓ≈(kn)1/d.
If n=1000, how big is ℓ?
| d | ℓ |
| 2 | 0.1 |
| 10 | 0.63 |
| 100 | 0.955 |
| 1000 | 0.9954 |
Almost the entire space is needed to find the 10-NN.
 Figure demonstrating ``the curse of dimensionality''. The histogram plots show the distributions of all pairwise distances
between randomly distributed points within d-dimensional unit squares. As the number of dimensions d grows, all distances concentrate within a very small range.
Figure demonstrating ``the curse of dimensionality''. The histogram plots show the distributions of all pairwise distances
between randomly distributed points within d-dimensional unit squares. As the number of dimensions d grows, all distances concentrate within a very small range.
Imagine we want ℓ to be small (i.e the nearest neighbor are truly near by), then how many data point do we need?
Fix ℓ=110=0.1 ⇒ n=kℓd=k⋅10d,
which grows exponentially!
Rescue to the curse: Data may lie in low dimensional subspace or on sub-manifolds. Example: natural images (digits, faces).
k-NN summary
k-NN is a simple and effective classifier if distances reliably reflect a semantically meaningful notion of the dissimilarity. (It becomes truly competitive through metric learning)
As n→∞, k-NN becomes provably very accurate, but also very slow.
As d→∞, the curse of dimensionality becomes a concern.
Reference
[1]Cover, Thomas, and, Hart, Peter. Nearest neighbor pattern classification[J]. Information Theory, IEEE Transactions on, 1967, 13(1): 21-27